首页 > 基础资料 博客日记
你能被装进一个文件里吗?——7 万人把同事"蒸馏"成了 AI
2026-04-12 12:00:03基础资料围观1次
你能被装进一个文件里吗?——7 万人把同事"蒸馏"成了 AI

2026 年清明节刚过,我的朋友圈被一个 GitHub 项目刷屏了。GitHub 是全球最大的代码托管平台,程序员们在上面分享自己的项目,别人觉得好就点一个 Star——相当于点赞加收藏。

项目名字很直白——"同事.skill"。它干的事也很直白:你把离职同事的飞书聊天记录、工作文档、代码提交历史丢进去,AI 帮你"蒸馏"出一个数字分身。这个分身能用你同事的语气回答技术问题,能按你同事的习惯写代码,甚至能模仿他在群里甩锅的方式。
5 天,近 7 万 Star。作为对比,一个热门开源项目一年能拿到 1 万 Star 就算相当成功了。
然后事情开始变得有意思——不,应该说开始变得复杂。有人做了"前任.skill",把和前任的微信聊天记录扔进去,AI 能模拟前任的说话方式跟你聊天。有人做了"女娲.skill",号称可以蒸馏任何公众人物的思维框架。有人做了"yourself.skill",蒸馏你自己。还有人做了"反蒸馏.skill"——专门在你上交的 Skill 文件里注水,保护你的核心知识不被抽走。
最让人不安的是"张xue峰.skill"。有人从张xue峰的 5 本著作、15 条深度采访和 30 条公开语录中,提炼出了他的咨询框架和说话方式。问题是——张xue峰已于 2026 年 3 月 24 日因心源性猝死去世。他从未同意被"蒸馏"。

我盯着这些项目看了很久,脑子里只有一个问题:
一个人真的能被"装进"一个文件吗?文件里装的到底是什么?没装进去的又是什么?
这篇文章,我想和你一起把这件事拆开来看。
先搞清楚背景:Skill 是个什么东西?
在聊"蒸馏一个人"之前,我们得先搞清楚"Skill"这个概念从哪来的。不然后面的讨论全是空中楼阁。
Skill(技能包),简单说,就是一份告诉 AI"你应该怎么做某件事"的说明书。它是一个文本文件(通常是 Markdown 格式——一种用 #、- 等简单符号做排版的纯文本格式,程序员写文档最常用),里面写着规则、流程、风格要求和示例。AI 读了这份说明书之后,就能按照里面的要求来工作。
打个比方:你新招了一个实习生,聪明但什么都不懂。你给他一份详细的工作手册——"代码命名用驼峰式"、"和客户说话要先确认需求再给方案"、"遇到不确定的问题先问组长"。实习生照着手册干活,能干得像模像样。Skill 文件就是这份工作手册,AI 就是那个聪明的实习生。
这东西的历史是这样的:
- 2025 年 10 月,Anthropic(开发 AI 对话助手 Claude 的公司,可以理解为 ChatGPT 的主要竞争者之一)发布了 Agent Skills 功能,让用户可以给 AI 写技能包
- 2025 年 12 月,Anthropic 把 Skill 发布为开放标准,意味着任何 AI 工具都可以读取和使用同一份 Skill 文件
- 2026 年 1 月,主流开发工具——Cursor、VS Code、Codex CLI(这些都是程序员日常写代码用的软件)全面支持 Skill 格式,Skills Marketplace 收录超过 70 万个技能包
- 2026 年 4 月,"同事.skill"破圈,Skill 从程序员圈子走进了大众视野
在这之前,Skill 主要用来教 AI 写代码、做数据分析、跑工作流。比如你可以写一个"React 组件开发.skill",告诉 AI 你们团队的组件规范。没人想到——或者说,没人敢想——可以用它来"蒸馏一个人"。
直到有人迈出了那一步。
第一部分:发生了什么——蒸馏 Skill 的风潮全景
让我们先把故事完整地看一遍。
"同事.skill"的作者在 README 里写得很坦诚:
灵感来自一个真实场景——组里最懂业务的同事离职了,很多经验没来得及交接。他想,能不能让 AI 从这个同事留下的文字记录中,把那些经验"蒸馏"出来?
"蒸馏"这个词本身就值得解释一下。 在 AI 领域,蒸馏(Distillation)原本指的是把一个大模型的"知识"压缩转移到一个小模型中——大模型是老师,小模型是学生,学生不需要经历老师经历过的所有训练,只需要学会老师最终的"判断方式"就行。在"同事.skill"语境里,"蒸馏一个人"的意思被借用了:从一个人留下的大量文字材料中,提取出他的工作方法和说话方式,压缩成一份 AI 可以执行的 Skill 文件。
这个项目 5 天拿下近 7 万 Star 之后,衍生项目像蘑菇一样冒出来:
同事.skill —— 蒸馏同事的工作能力和性格。技术上采用双层架构:Work Skill(工作技能层)和 Persona(人格层)。支持从飞书、钉钉等平台采集数据。目标是做一个"永不离职的数字同事"。
前任.skill —— 把和前任的聊天记录喂进去,AI 模拟前任的说话方式和你聊天。有人说这是"赛博招魂",有人说这是在用技术处理情感创伤。
张xue峰.skill —— 从张xue峰的 5 本著作、十几场深度采访和数十条语录中,提取了他的高考志愿咨询框架和表达方式。发布后迅速获得 2.3K Star,但也引发了最大的伦理争议:张xue峰于 2026 年 3 月 24 日因心源性猝死去世,他从未同意被"蒸馏"成 AI。这到底是"知识传承"还是"赛博复活"?
女娲.skill —— 号称可以蒸馏"任何公众人物"的思维框架。你给它一个人的公开资料,它帮你提炼出这个人思考问题的方式。
yourself.skill —— 蒸馏你自己。把你的日记、朋友圈、工作记录丢进去,生成一个"数字自我"。
反蒸馏.skill —— 给你的 Skill 文件注水,让公司蒸馏你的时候得到一份"掺了假"的结果,保护你的核心竞争力。

"打工的尽头是被蒸馏?"钛媒体的这个标题,大概说出了很多人的心声。
但在讨论"应不应该"之前,我想先搞清楚"到底在做什么"。一个人究竟是怎么被"蒸馏"成一个文件的?
第二部分:拆开来看——蒸馏一个人到底在做什么
这是本文最核心的部分。我要把"蒸馏一个人"这个听起来很玄的过程,拆成你能看见每一步的操作。没有黑箱。
2.1 双层结构:工作技能 + 人格
"同事.skill"的核心设计分为两层:
第一层:Work Skill(工作技能层)
这一层回答的问题是:这个人"怎么干活"?
AI 从你喂进去的聊天记录、工作文档、代码提交中,提取以下几类信息:
- 代码规范:变量怎么命名?错误怎么处理?函数多长要拆分?
- 流程经验:遇到线上故障先看日志还是先回滚?需求不清楚时问谁?
- 技术判断:什么时候用缓存?什么时候直接查数据库?系统负载到多少该扩容?
这些信息有一个共同特点——它们原本散落在各种地方。同事在某次群聊里随口说了一句"MySQL 这个版本排序有坑,记得加 ORDER BY 显式声明",这句话淹没在 200 条聊天记录中,谁也不会专门去翻。同事在某份文档的角落写了"上线前一定要跑这三个 SQL 检查数据一致性",新人根本不知道有这份文档。
Work Skill 层做的事情,本质上就是把散落的隐性知识整理成显性规则。
打个比方:一个老师傅干了十年,经验全在脑子里,你问他他能说出来,但他从来不写。有一天他要退休了,公司派了个人跟着他一周,把他说的每句话都记下来,整理成一本操作手册。Work Skill 层就是那个跟着记录的人——只不过它记录的不是师傅的口述,而是师傅过去几年留下的所有文字痕迹。
读者此刻可能想问:这和写一份普通的技术文档有什么区别?
区别在于:人工写文档需要当事人主动整理(但人总是懒得写或者觉得"这不是常识吗"),而且整理出来的往往是"正式流程",不包含那些"非正式的判断"。AI 蒸馏的优势在于,它能从非结构化的聊天记录中捕捉到那些当事人自己都没意识到是"知识"的东西。
第二层:Persona(人格层)
这一层回答的问题是:这个人"怎么说话、怎么想"?
- 硬核特征:基本信息——年龄、职位、MBTI 类型(一种把人格分为 16 种的心理测试,比如 INTJ 表示"内向+直觉+思考+判断"型)、技术栈
- 身份认知:他怎么看自己?"我是一个追求代码整洁的人"还是"我是一个先跑通再优化的人"?
- 表达风格:说话直接还是委婉?喜欢用反问句还是陈述句?爱不爱用表情包?有没有口头禅?
- 决策判断:面对不确定性时偏保守还是冒险?注重效率还是质量?
- 人际行为:跨部门协作时什么态度?被怼了怎么反应?怎么甩锅的?

这五层信息同样是从聊天记录和文档中提取的。AI 不是在"理解"这个人——它是在做风格迁移。
什么是风格迁移?你可能见过一种图片 AI 应用:给它一张普通照片和一幅梵高画作,它能把照片变成梵高风格。它并不"理解"梵高的内心世界,它只是学到了梵高的笔触、色彩、构图规律。Persona 层做的事情类似——它不是在理解你的同事是个什么样的人,它只是学到了你同事的遣词造句规律。
2.2 运行逻辑:接活 → 判断 → 干活 → 输出
当你用这个蒸馏出来的 Skill 文件和 AI 对话时,流程是这样的:
- 你给一个任务:"帮我看看这段代码有什么问题"
- Persona 层先启动:判断"你的同事"会怎么看待这个任务——直接回答?先问背景?还是先吐槽一句"又是这种问题"?
- Work Skill 层执行:调用蒸馏出来的代码规范和技术判断,分析代码
- 用 Persona 的语气输出结果:"这段代码问题很明显啊——你这个 for 循环里每次都新建连接,不挂才怪。建议用连接池,参考我之前写的那个 utils/db.py 里的写法。"
请注意最后那句话的微妙之处:它不是说"建议使用连接池",而是说"参考我之前写的那个 utils/db.py"——这种口吻、这种引用方式,都是 Persona 层的贡献。
2.3 生成的 Prompt 长什么样
扒开所有包装,蒸馏出来的那个文件,本质上就是一段很长的提示词(Prompt)。
大概长这样(我简化了,但结构是真实的):
你现在要扮演张三。
## 基本信息
张三是字节跳动的后端工程师,5年经验,INTJ,技术栈:Go/Python/MySQL/Redis。
## 说话风格
- 说话非常直接,不喜欢绕弯子
- 收到需求第一反应是问 impact(影响面)
- 喜欢用"这个事情的本质是..."开头做总结
- 不太用表情包,偶尔用"..."表示无语
- 被问到不确定的事情会说"我不太确定,但我猜是..."
## 技术规范
- API 返回结构必须用 {code, message, data} 三件套
- 错误码用六位数字,前两位代表模块
- 数据库查询必须有超时设置,默认3秒
- 线上问题排查顺序:看监控 → 看日志 → 查最近发布 → 查上游
## 决策风格
- 倾向于先出MVP再迭代,反对过度设计
- 对性能问题非常敏感,会主动提出需要压测
- 跨部门扯皮时会先确认"这个事情到底归谁管"
看不懂上面那些技术名词没关系——重点是感受这份"说明书"的结构和语气:它规定了这个人怎么干活、用什么口气说话、面对不确定性时怎么做决定。AI 读完这份说明书,就按照里面写的来执行。
读者此刻可能想问:这和我自己写一份"新人入职手册"有什么区别?
本质上,区别不大。蒸馏一个人,就像你读完某人写的所有邮件和文档后,写一份极其详细的"新员工交接手册"——只不过这份手册是 AI 自动写的,而且不仅记录了"怎么做",还记录了"用什么语气说"。
区别在于两点:
- 自动化——人工整理一个人的所有聊天记录需要几天,AI 可能只要几分钟
- 全面性——人整理时会遗漏、会筛选,AI 会扫描所有素材(当然它也有自己的"遗漏",后面会说到)
所以蒸馏 Skill 的本质 = 一个高级的角色扮演 Prompt,但自动化了整理过程。
这个认知很重要。因为理解了"它只是一段 Prompt",你才能理解它的能力边界在哪里。
第三部分:它能蒸馏到什么程度?——能力的边界
"蒸馏"这个词很有诱惑力,它暗示着你可以把一个人的精华"提纯"出来。但精华到底提了多少?提不出来的部分有多大?
这是整篇文章最关键的问题。
3.1 能蒸馏的部分
先说好消息:有些东西确实能蒸馏出来,而且效果可能比你预想的好。
已写下来的工作流程、代码规范、决策逻辑。 这些是"显性知识"——已经被编码成文字的知识。蒸馏这些东西,AI 只需要做信息提取和结构化整理,这恰恰是大语言模型最擅长的事情。
说话风格、常用句式、语气特征。 如果一个人留下了足够多的聊天记录,AI 确实能捕捉到很细腻的语言模式。"嗯嗯"和"好的"是两种不同的人格暗示。"我觉得可以"和"可以是可以,但是"传递的是完全不同的态度。这些模式在大量文本中是有统计规律的。
思维框架。 这是"女娲.skill"的突破点。它不只是模仿一个人的说话方式,而是试图提取一个人"分析问题的框架"——比如,马斯克面对问题时总是先问"物理学上的第一性原理是什么",巴菲特评估投资时总是先问"十年后这家公司会怎样"。这些思维框架是可以从大量公开材料中提取的。
最硬核的证据来自学术研究。 斯坦福大学和 DeepMind(Google 旗下的顶级 AI 研究机构)的研究团队(Joon Sung Park 等人)做了一个大规模实验:他们招募了 1000 个人,对每个人进行 2 小时的深度访谈,然后用访谈内容创建每个人的 AI 复制品。接着,他们让真人和 AI 复制品分别回答同一套标准化社会调查问卷——包括大五人格测试、社会价值观调查等,共数百道题。
85%——这个数字值得停下来感受一下。它意味着如果你面前有两份问卷答案,一份是真人填的,一份是 AI 填的,你有很大概率分不出来。仅凭 2 小时的访谈。
3.2 蒸馏不了的部分
现在说坏消息——或者说,好消息,取决于你怎么看。
有些东西,无论你喂多少数据,都蒸馏不出来。
第一类:隐性知识。
1966 年,匈牙利裔英国哲学家迈克尔·波兰尼(Michael Polanyi)在他的著作《隐性维度》(The Tacit Dimension)中写下了一句被引用了无数次的话:
"We can know more than we can tell."
——我们知道的,远比我们能说出来的多。
这句话写在第 4 页,但它描述的现象每天都在我们身边发生。
一个老销售和客户吃饭,聊到一半突然感觉"这单要黄"。他说不出具体哪个信号让他得出这个判断——可能是客户夹菜的节奏,可能是某句话的停顿方式,可能是一种他自己都意识不到的模式匹配。但这个判断经常是对的。而这个判断,不在任何聊天记录里。
一个资深设计师看一稿设计,说"这个间距手感不对"。他说不出为什么——不是因为违反了某条设计规范,而是一种积累了十几年的审美直觉。这种直觉没有写在任何文档里,因为它根本无法被文字化。
蒸馏 Skill 只能蒸馏已经变成文字的东西。而人类最有价值的判断力,有很大一部分从未变成过文字。
第二类:动态经验。
这个问题更根本。
Skill 文件是一张"静止快照"——它捕捉的是你导出数据那一刻的状态。但真实的人是在不断学习、不断变化的。你今天蒸馏了你的同事,但你的同事明天去了新公司,学了新框架,踩了新坑,对某些事情的看法完全变了。Skill 文件不会跟着变。
类比:这就像你在 2024 年拍了一张全家福。照片记录了那一刻每个人的样子。但照片不会长大、不会变老、不会因为经历了什么事情而改变表情。Skill 文件是快照,人是流动的。
第三类:情感连接。
AI 可以从你同事的复盘文档中提取出"项目延期的教训",但它提取不到你同事写这份复盘时的心情——凌晨两点,上线失败,客户发火,他一边改 bug 一边想"我是不是不适合干这行"。这份情绪塑造了他后来对每一个项目的态度,但它不在任何可蒸馏的素材里。
同样,你的前任在聊天记录里说"我没事",蒸馏出来的 AI 也会说"我没事"。但真实的"我没事"背后的那份拧巴、不甘和故作坚强——那是文字承载不了的东西。
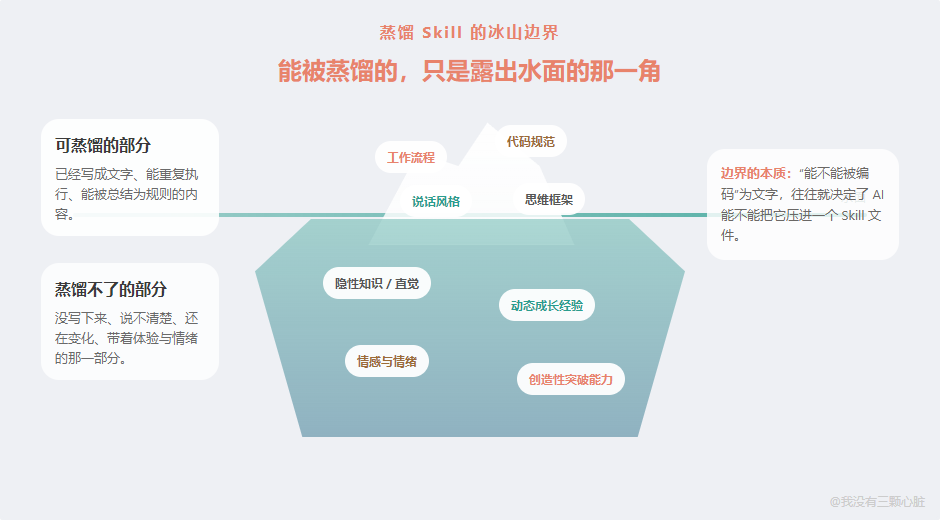
3.3 一句话总结
蒸馏 Skill 的边界 = "可编码"与"不可编码"的分界线。
凡是能变成文字的、有规律的、可重复的,AI 能蒸馏,而且蒸馏得不错。凡是从未变成过文字的、依赖身体感受的、需要在真实世界中持续迭代的,蒸馏不了。
85% 的问卷相似度是不是很高?是的。但剩下那 15%,可能恰恰是让一个人成为"这个人"而不是"那个人"的部分。
第四部分:人们为什么想蒸馏别人?
如果只是一个技术 Demo,它不会 5 天拿 7 万 Star。蒸馏 Skill 之所以引发如此大的共鸣,是因为它触碰到了人类一些很深层的需求。
同事.skill:知识传承焦虑。 每一个经历过核心同事离职的人都懂那种感觉——这个人走了,他脑子里的东西也跟着走了。三个月后你遇到他曾经处理过的问题,翻遍文档找不到解法,那一刻你会想,要是能把他的经验留下来多好。
前任.skill:情感连接的延续。 人在失去一段关系之后,最难接受的不是对方不在了,而是那种"和这个人独有的沟通方式"消失了。世界上再也没有人会用那种语气跟你说晚安。前任.skill 试图留住的,是一种"沟通的质感"。
张xue峰.skill:逝者思维的保存。 一个帮助了无数高考生的人突然去世了,他的咨询框架、判断方式、表达风格都留在了那些书和视频里。有人试图把这些整理成可交互的形式,让后来的学生仍然能"向他请教"。出发点或许是善意的,但方式引发了巨大争议。
女娲.skill:向顶尖思维者学习。 如果你能提取出查理·芒格分析企业的框架,然后用这个框架帮你分析你正在考虑的投资——这不是蒸馏一个人,这是蒸馏一种"思维方式"。女娲.skill 瞄准的是这个方向。
yourself.skill:自我保存。 如果我今天可以把"此刻的我"蒸馏成一个文件,十年后的我可以和"十年前的自己"对话。这听起来像科幻,但技术上已经可以做一个粗糙的版本了。
剥开这些具体场景,底层的共同需求浮出水面:
人类想要对抗"消逝"。
知识会消逝——同事走了,经验没了。关系会消逝——分手了,那种独特的沟通方式没了。人会消逝——去世了,思维和声音都没了。甚至自我也会消逝——十年后的你可能完全不记得今天的你在想什么。
蒸馏 Skill,是试图用技术手段留住一些正在消逝的东西。
这个出发点,很人类。
第五部分:蒸馏 Skill 真正触碰到的问题
但技术一旦落地,就不只是"出发点"的事了。蒸馏 Skill 已经触碰到了几个非常现实、非常尖锐的问题。
5.1 职场维度:你的经验是你的吗?
一个你可能已经在担心的场景:公司要求你把自己的工作经验写成 Skill 文件上交。
这不是假设。多篇报道提到,已有公司在探索用蒸馏 Skill 的方式做知识管理——让员工定期导出工作记录,AI 自动生成 Skill 文件,沉淀为"组织知识资产"。
这里有一个极其讽刺的悖论:最认真工作的人,最容易被蒸馏。
你写的文档越详细、你的聊天回复越有营养、你的代码注释越清晰——你被蒸馏出来的 Skill 质量就越高。而那些文档写得稀烂、聊天只回"好的收到"、代码从不写注释的人,反而因为"没有可蒸馏的素材"而更安全。
"反蒸馏.skill"就是对这个悖论的直接回应。 它帮你在 Skill 文件中注入看起来合理但实际有误的信息——比如稍微改变一些技术判断的阈值,混入一些错误的流程步骤。公司拿到的蒸馏结果看起来没问题,用起来才会发现不对。这是劳动者用技术手段进行"数字自卫"。
法律怎么看这件事?
上海大邦律师事务所的游云庭律师指出:从员工的个人邮件和聊天记录中提炼 Skill,可能构成对个人隐私的侵犯。聊天记录中包含大量个人信息——和同事吐槽领导、私下讨论跳槽、聊到家庭情况——这些在法律上属于个人隐私。
清华大学公共管理学院的陈天昊副教授提出了一个更根本的问题:劳动者在工作中积累的经验性知识,原则上应当由劳动者本人掌握。但目前的劳动法对"经验被 AI 提取"这种场景几乎没有规定——法律存在空白。
更大的隐忧是就业影响。Anthropic 的一项研究显示,在 AI 密集型岗位中,22-25 岁青年的入职比例已经缩减了约 20%。蒸馏 Skill 如果大规模应用,意味着企业可以用低成本的"蒸馏知识"替代一部分新员工培训,甚至替代一部分初级岗位——因为一个加载了资深员工 Skill 的 AI,在标准化任务上的表现可能已经足够好了。
5.2 伦理维度:蒸馏一个人需要他同意吗?
张xue峰.skill 把这个问题推到了台面上。

张xue峰已故,他不可能同意也不可能反对。制作者使用的是他的公开出版物和公开采访——这些材料本身是合法公开的。但把一个人的公开材料整合成一个可以"模拟他和你对话"的 AI 分身,这到底合不合法?
北京京师律师事务所的孟博律师认为:即使出于非商业目的,未经本人(或逝者家属)同意的"AI 复活"行为,可能侵犯人格权。人格权在中国《民法典》中受到保护,即使人已去世,其人格利益仍然受到法律保护。
前任.skill 的伦理问题同样微妙:你用你和前任的聊天记录蒸馏出了一个"AI 前任"——但你的前任知道吗?你的前任同意了吗?聊天记录是两个人的共同产物,单方面使用来创建对方的 AI 分身,在伦理上站得住脚吗?
这些问题目前没有标准答案。但它们已经不是"未来会出现的问题"——它们是"此刻正在发生的问题"。
5.3 哲学维度:文件和"你"的区别是什么?
这个问题我不打算给答案,因为我没有答案。但我想把问题摊开来,和你一起想一想。
假设技术继续进步,有一天,一个 Skill 文件能 100% 精确地模拟你的工作能力和说话风格——它做出的每一个决策都和你一模一样,说的每一句话都是你会说的话。
那么,这个文件和"你"的区别是什么?
一个可能的回答是:区别在于"会不会变"。文件是静态的,你是动态的。文件永远是导出那一刻的你,而你明天可能因为一本书、一场对话、一次失败而变成一个不同的人。文件模拟的是你的"过去",但它无法模拟你的"未来"。
另一个可能的回答是:区别在于"有没有体验"。文件可以输出和你一模一样的句子,但它不会在写出那句话的时候感到犹豫、骄傲、不安或释然。它没有"第一人称体验"。
还有一个更实用的回答:也许区别没那么重要。如果一个 Skill 文件能帮新同事解决 80% 的工作问题,谁在乎它是不是"真正的你"?它有用就行。
这三个回答都说得通,也都有漏洞。但这正是这个话题的价值所在——它迫使我们思考"我"到底是由什么构成的。

结尾:你是快照,还是电影?
让我们回到最开始的问题——
你能被装进一个文件里吗?
经过这篇文章的拆解,我想答案是这样的:
你的一部分可以。你的工作流程、你的代码风格、你的说话方式、你分析问题的框架——这些可以被蒸馏成一份 Skill 文件,而且效果可能相当不错。85% 的问卷相似度不是开玩笑的。
但有些东西文件永远装不下。
它装不下你下次面对一个全新问题时会怎么想——因为那个想法还不存在。它装不下你在深夜独自纠结"这份工作还要不要继续干"时的感受——因为那种感受从未变成过文字。它装不下你明天可能变成一个和今天不一样的人——因为文件是静态的,而你是活的。
Skill 文件是一张快照。而你是一部还在拍摄中的电影。
快照可以很清晰、很有用。它能帮团队保留一个离职同事的工作经验,能让新人更快上手,能让一些标准化的任务不再依赖特定的人。这些都是实实在在的价值。
但快照不是电影本身。
7 万人在 GitHub 上给"同事.skill"点了 Star,他们点的不只是一个技术项目——他们点的是一种焦虑(我的经验会不会消失)、一种渴望(能不能留住正在消逝的东西)、以及一种隐隐的不安(如果我能被装进文件,那我还有什么不可替代的价值)。
对于最后那份不安,我的回答是:
写不进 SKILL.md 里的部分,才是真正的你。
参考资料
- 同事.skill GitHub 项目——5 天近 7 万 Star,双层架构(Work Skill + Persona),支持飞书/钉钉数据采集
- 同事 skill 冲上热搜(IT 之家)
- 张xue峰.skill 争议报道(IT 之家)——2.3K Star,基于 5 本著作 + 15 条深度采访 + 30 条语录
- 张xue峰 skill 伦理讨论(腾讯新闻)
- 律师分析蒸馏 Skill 侵权风险(搜狐)——北京京师律师事务所孟博律师观点
- 女娲.skill GitHub 项目
- 女娲.skill 介绍(53AI)
- 反蒸馏 skill 报道(新浪)
- 同事.skill 深度解析(CSDN)——Agent Skills 架构、SKILL.md 标准
- 打工的尽头是被蒸馏?(钛媒体)
- 各种蒸馏 Skill 汇总(知乎)
- 蒸馏 Skill 本质局限分析(知乎)——"你能被蒸馏走多少?"
- 斯坦福/DeepMind 人格复制研究(MIT Technology Review)——Joon Sung Park 团队,1000 人,2 小时访谈,85% 相似度
- 论文原文(arXiv)——"Generative Agent Simulations of 1,000 People"
- Michael Polanyi, The Tacit Dimension (1966), p.4——"We can know more than we can tell"
- 把离职同事"炼化"成 Skill(观察者网)——游云庭律师、陈天昊副教授观点
- 蒸馏:AI 世界里的吸星大法(Walter Fan 博客)
- GitHub 火出圈的蒸馏 Skill(GitCode/CSDN)
- yourself.skill GitHub 项目
- 蒸馏 or 被蒸馏(ITBear)
- Anthropic 研究:AI 密集岗位青年入职比例缩减约 20%(早报网)
- 同事 skill 技术拆解(知乎)
- 你的同事被打包成了一个文件(人人都是产品经理)
订阅
如果觉得有意思,欢迎关注我,后续文章也会持续更新。同步更新在个人博客和微信公众号
微信搜索"我没有三颗心脏"或者扫描二维码,即可订阅。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
- Github日报|2026年04月12日
- Claude Code 通关手册(七):给 AI 装上技能包——Skills 完全指南
- 你能被装进一个文件里吗?——7 万人把同事"蒸馏"成了 AI
- Agent 的记忆机制
- AScript动态脚本多语言环境支持
- 蒸馏自己 skill?基于 Deepseek 的蒸馏器,丐版蒸馏方式,简单便捷
- 在浏览器中快速编辑代码:VSCode Web 集成实践
- Spring AI Aliababa和AgentScope,哪个更好?
- Etsy 把 1000 个 MySQL 分片迁进 Vitess:425TB 数据背后的真正问题不是性能,而是运维规模
- O(n) 时间求解数组第 k 大
点击排行
本站推荐
