首页 > 基础资料 博客日记
深度学习如何重塑三维重建:从任务定义到工程落地全流程解析
2026-04-29 15:30:05基础资料围观1次
前言
三维重建正在从“可视化展示”走向“可交付、可运维、可闭环”的工程系统。过去,行业更多依赖传统几何方法解决位姿、深度和稠密建模问题;而在复杂场景、跨设备部署和长期稳定运行的要求下,仅靠单一算法已难以满足实际需求。深度学习的价值也因此发生转变:不再只是追求某个模块的离线精度极限,而是嵌入重建全链路,提升鲁棒性、泛化性和系统效率。
本文围绕三维重建Pipeline的关键环节展开,从任务入口定义、数据采集治理、几何前端增强,到深度与多视图几何、稠密表示生成、外观恢复、动态时序一致性、语义增强,以及后处理与部署优化,系统梳理深度学习在各阶段的可落地切入点。核心目标是给出一套面向工程实践的方法框架:先明确场景与目标约束,再用“学习增强 + 几何约束 + 质量闭环”的组合范式,构建可持续演进的三维重建系统。
0. 任务入口与场景定义(决定后续技术路线)
三维重建项目中,深度学习方法是否有效,往往不取决于“模型是否先进”,而取决于任务定义是否准确。入口阶段需要先明确输入模态、场景属性和业务目标,这三者会直接决定后续在位姿估计、深度估计、表示学习和部署优化上的方法选择。
0.1 输入模态:决定可利用信息上限
1) 单目图像(Monocular RGB)
- 优势:采集门槛低、数据来源广、硬件成本最低。
- 局限:天然缺乏绝对尺度与深度约束,易受纹理缺失和光照变化影响。
- 深度学习典型作用:
- 单目深度估计提供伪几何先验;
- 语义分割辅助结构恢复(墙、地、天等布局);
- 学习型特征匹配提高SfM鲁棒性。
- 适用场景:互联网图像重建、轻量级移动采集、低成本原型验证。
![在这里插入图片描述]()

2) 多视图图像(Multi-view RGB)
- 优势:有视差约束,可形成稳定几何恢复基础。
- 局限:依赖视角覆盖质量,采集组织成本较高。
- 深度学习典型作用:
- 学习型MVS网络替代传统匹配代价;
- 基于置信度的深度融合和异常剔除;
- 在弱纹理区域引入先验提升重建完整性。
- 适用场景:文物数字化、工业零件逆向、室内外高保真重建。
![在这里插入图片描述]()
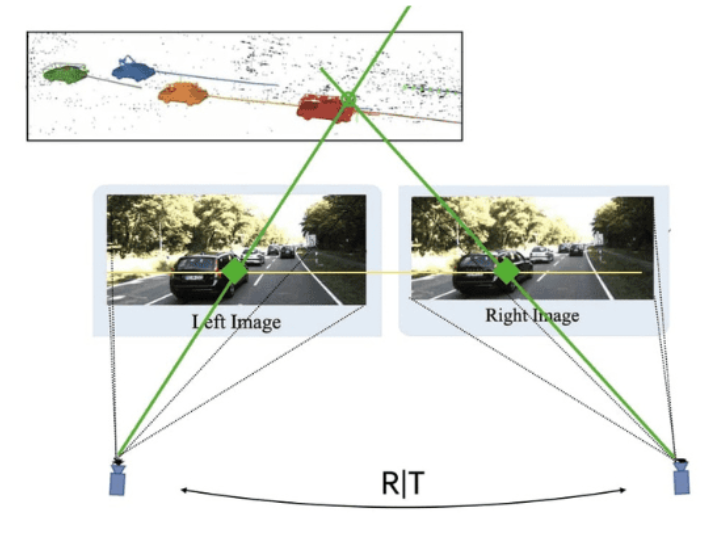
3) 视频序列(Video)
- 优势:天然具备时序连续性,利于位姿估计和稠密跟踪。
- 局限:动态物体、运动模糊和滚动快门会引入误差积累。
- 深度学习典型作用:
- 关键帧选择和动态区域分割;
- 时序一致性约束的深度估计;
- 联合VO/SLAM的漂移抑制。
- 适用场景:机器人巡检、手机扫描、自动驾驶场景建图。
![在这里插入图片描述]()

4) RGB-D / 深度相机
- 优势:直接获得深度,几何恢复稳定,工程落地快。
- 局限:深度噪声、空洞、量程受限;户外强光环境表现不稳定。
- 深度学习典型作用:
- 深度补全与去噪;
- RGB引导的边缘细节修复;
- 多帧融合中的不确定性建模。
- 适用场景:室内扫描、机械臂抓取、近距重建任务。
![在这里插入图片描述]()

5) LiDAR 点云(可与视觉融合)
- 优势:几何精度高、远距离测量稳定。
- 局限:点云稀疏、语义信息弱、设备成本高。
- 深度学习典型作用:
- 点云补全和上采样;
- LiDAR-视觉融合提升稠密重建质量;
- 学习型配准与跨传感器标定。
- 适用场景:自动驾驶、高精地图、室外大尺度重建。
![在这里插入图片描述]()
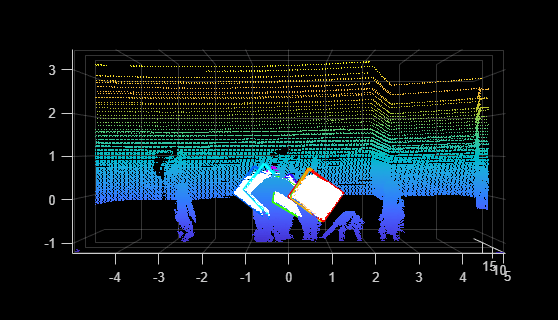
0.2 场景属性:决定方法的可行边界
1) 室内 vs 室外
- 室内:结构规则、尺度较小、遮挡密集,适合语义先验与RGB-D融合。
- 室外:光照变化剧烈、尺度大、动态目标多,需更强鲁棒配准与分块重建策略。
2) 静态 vs 动态
- 静态场景:可采用传统SfM/MVS与NeRF类方法获得高质量结果。
- 动态场景:必须引入动态分割、时序建模与4D表示,否则容易出现重影、几何撕裂和位姿漂移。
3) 小物体 vs 大场景
- 小物体重建:强调局部细节、边界和纹理保真,常用高分辨率多视图与隐式表示。
- 大场景重建:强调全局一致性与效率,需分区建图、层级表示和内存优化。
4) 材质复杂度
- 反光、透明、弱纹理区域是传统几何方法难点。
- 深度学习可通过先验补偿和可微渲染提升稳定性,但仍需多模态或物理约束辅助。
0.3 目标定义:决定最优解而非最强模型
实际项目通常不是“精度越高越好”,而是多目标折中。建议在立项时先定义主目标优先级:
1) 几何精度优先
- 关注绝对/相对误差、边缘细节、拓扑正确性。
- 方法倾向:学习型MVS + 高质量融合 + 后处理修复。
- 代价:算力和处理时长较高。
2) 视觉观感优先
- 关注纹理清晰度、材质真实感和新视角渲染质量。
- 方法倾向:NeRF/3DGS及其高保真外观建模分支。
- 风险:几何可编辑性和工程部署复杂度上升。
3) 实时性优先
- 关注端侧推理延迟、吞吐和功耗。
- 方法倾向:轻量网络、稀疏表示、模型压缩与增量更新。
- 折中:在复杂场景下可能牺牲精度与完整性。
4) 成本与可部署性优先
- 关注数据采集成本、训练成本、维护成本与稳定性。
- 方法倾向:混合式方案(传统几何 + 深度学习关键模块增强),逐步迭代替换。
0.4 深度学习切入点选型矩阵(入口阶段建议)
| 约束条件 | 优先切入环节 | 推荐策略 |
|---|---|---|
| 数据少、标注少 | 位姿/匹配、深度补全 | 使用预训练模型 + 几何一致性自监督 |
| 设备算力弱 | 前端特征与轻量深度网络 | 模型蒸馏、量化、关键帧推理 |
| 场景动态多 | 动态分割与时序建模 | 静动态解耦 + 4D一致性约束 |
| 需要高保真渲染 | 外观建模与神经表示 | NeRF/3DGS + 几何先验融合 |
| 工业高精度需求 | 深度估计与融合优化 | 学习MVS + 不确定性过滤 + 网格修复 |
1. 数据采集与质量控制
在三维重建项目中,采集质量通常决定结果上限。深度学习在这一环节的核心价值,不是“直接生成三维”,而是提前识别和抑制会在后续SfM/MVS/NeRF阶段被放大的误差源,包括模糊、曝光异常、视角覆盖不足、动态干扰和域偏移。
工程上可以把本章理解为:用学习方法做数据入口治理,把坏数据尽量挡在Pipeline前端。
1.1 本环节在重建Pipeline中的定位
数据采集与质量控制是重建流程的“前端门控层”,对后续模块有连锁影响:
深度学习在该阶段应聚焦两类任务:
- 采集前规划:视角策略、路径建议、采集规范。
- 采集中筛选:质量评估、关键帧选择、异常检测与自动回采。
1.2 深度学习可落地的关键能力
1.2.1 图像质量评估(IQA)
目标是自动识别“不适合进入重建”的帧,常见检测维度:
- 清晰度:运动模糊、失焦、压缩伪影。
- 曝光质量:过曝、欠曝、强反差区域。
- 纹理可用性:大面积纯色或弱纹理导致匹配困难。
- 反光/透明区域占比:玻璃、镜面会干扰几何一致性。
落地方式:
- 使用无参考IQA网络(NR-IQA)打分,并按阈值过滤。
- 将IQA分数接入采集App实时提示(“请减速”“请补拍该区域”)。
- 对边缘可用帧不直接丢弃,可降权进入后续融合。
工程收益:
- 降低匹配失败率与重建噪声。
- 减少后处理修复成本。
- 缩短“采完才发现不能用”的返工周期。
1.2.2 关键帧筛选与视角覆盖评估
重建不是帧越多越好,而是视角覆盖越完整越好。深度学习可用于关键帧抽取和覆盖度评估:
- 相邻帧冗余检测:避免近重复帧堆积。
- 视角多样性评分:优先保留基线充分、信息增益高的帧。
- 覆盖空洞检测:识别尚未拍摄到的区域。
可采用策略:
- 学习型帧表示 + 聚类筛选关键帧。
- 结合几何启发(视差、重叠率)进行混合筛选。
- 针对视频采集,做“在线关键帧决策”,边采边控。
工程收益:
- 在相近精度下减少数据量、降低算力消耗。
- 提高场景完整性,降低“某一面缺失”的概率。
1.2.3 动态干扰与异常内容检测
动态目标(行人、车辆、摆动物体)会破坏静态场景假设。深度学习可前置识别并隔离这类区域:
- 语义分割/实例分割:识别潜在动态类别。
- 光流一致性检测:发现运动区域与遮挡边界。
- 时序异常检测:跳帧、剧烈抖动、滚动快门异常。
落地建议:
- 静态重建任务中,对动态区域打掩码,降低其在匹配与融合中的权重。
- 对高动态片段触发“重采建议”。
- 记录动态占比,作为场景难度标签输入后续模块。
1.2.4 域适配与数据增强(提升泛化)
同一重建模型常在不同设备、不同光照和不同环境下退化。采集阶段可通过学习策略做“分布对齐”:
- 风格迁移增强:模拟目标域光照/色彩。
- 几何一致增强:旋转、缩放、裁剪时保持标注几何关系。
- 真实-仿真混合训练:降低真实数据稀缺带来的偏差。
目标是让后续位姿估计和深度网络在跨场景时更稳定,而不是仅在单一数据集上最优。
1.2.5 主动采集(Active Reconstruction)
主动采集强调“系统告诉采集者下一步拍哪里最有价值”,是高性价比提质方向:
- 预测当前重建不确定性热区。
- 推荐下一视角以最大化信息增益。
- 在移动端或机器人端实时给出路径建议。
该能力可显著减少盲拍和重复拍摄,特别适用于大场景和复杂结构物体。
1.3 典型实现架构(工程可直接套用)
一个常见的数据采集质量控制流水线如下:
- 输入帧流:相机/视频实时输入。
- 质量评分模块:IQA + 纹理可用性 + 曝光评估。
- 动态检测模块:语义分割 + 光流异常检测。
- 关键帧决策模块:冗余抑制 + 覆盖度优化。
- 反馈模块:实时提示用户补拍/调整角度。
- 数据缓存与打标:记录质量分、动态比例、覆盖指标。
该结构本质是“在线数据治理层”,建议作为所有重建任务的通用前端。

1.4 指标体系:如何衡量这一环节是否有效
建议将本章节效果量化为“前端质量指标 + 后端收益指标”两类。
1.4.1 前端质量指标
- 可用帧率(可进入重建的帧占比)。
- 平均质量分与低质量帧占比。
- 关键帧压缩率(在保留信息前提下的数据减量)。
- 场景覆盖度(视角覆盖与盲区比例)。
- 动态区域占比与剔除准确率。
1.4.2 后端收益指标
- SfM匹配内点率与位姿求解成功率。
- 深度图完整性与噪声水平。
- 最终点云/网格完整度(如F-score、Completeness)。
- 端到端处理时长与返工率。
若前端质量控制有效,通常会看到:后端精度提高 + 总时长下降 + 人工干预减少。
1.5 成本与代价(必须提前评估)
深度学习前置提质虽有效,但也引入成本:
- 额外推理开销:实时评分与分割会占用边端算力。
- 阈值调参成本:不同场景需不同质量门限。
- 错杀风险:过严筛选可能丢失关键视角帧。
- 系统复杂度提升:多模块联动增加工程维护负担。
优化建议:
- 采用分级策略:轻量模型在线筛选,重模型离线复检。
- 关键模块做可回退设计(保留原始帧索引,支持重跑)。
- 按场景维护参数模板(室内、室外、夜间、强反光)。
1.6 本节结论
数据采集与质量控制是三维重建中最容易被低估、但投入产出比最高的深度学习应用点。
其核心不是追求复杂模型,而是建立一套稳定的前端治理机制:先确保输入可重建,再讨论后端高精度。
在工程实践中,建议优先落地以下三项能力:
- 在线图像质量评估(清晰度/曝光/纹理可用性)。
- 关键帧与覆盖度联合优化(去冗余但不丢信息)。
- 动态干扰检测与掩码化处理(保障静态重建假设)。
做到这三点,通常即可显著提升整条Pipeline的稳定性与最终重建质量。
2. 相机标定、位姿估计与配准
在三维重建Pipeline中,相机标定、位姿估计与多源配准构成几何前端。该阶段的误差会被后续深度估计、融合和网格化持续放大,因此这是深度学习“最值得投入”的增强点之一。
从工程角度看,本章节目标是回答三个问题:相机是否被正确建模、位姿是否稳定可解、跨帧/跨传感器是否能精确对齐。
2.1 本环节在Pipeline中的作用边界
该环节向后续模块提供“统一坐标系下的几何基础”,主要输出包括:
- 内参/畸变参数:焦距、主点、径向与切向畸变。
- 外参与轨迹:相机在世界坐标中的位姿序列。
- 跨源对齐关系:视觉、IMU、LiDAR、深度相机等传感器外参。
若该环节不稳定,常见连锁问题包括:
- 特征匹配多但可用内点少,RANSAC难收敛。
- 局部轨迹可解但全局漂移明显,闭环后仍不一致。
- 多传感器融合出现“重影”或系统性偏移。
- 后续稠密重建出现拉伸、错层、重复结构。
因此,深度学习在此阶段的价值不是替代几何约束,而是增强其鲁棒性:几何方法负责可解释性,学习方法负责抗噪与泛化。
2.2 深度学习在标定中的应用
2.2.1 学习型畸变与内参估计
传统标定依赖标定板和离线流程,工业环境下维护成本高。学习方法可用于在线校正与快速重估:
- 基于图像线结构的畸变回归(直线应保持直线)。
- 基于重投影一致性的弱监督内参优化。
- 多设备迁移学习,减少每台设备单独标定成本。
输入:是图像(单帧或多帧)以及可选的线特征/匹配点/初始参数等约束信息。
输出:是相机内参和畸变参数(常带置信度或重投影误差),用于去畸变和后续位姿求解
2.2.2 自标定与在线重标定
在长期运行系统中,相机参数可能随时间漂移。可用深度学习做漂移监测与触发式重标定:
- 监测重投影误差分布是否异常。
- 在特定阈值触发时启动在线微调。
- 对高风险设备分配更频繁重标定周期。
该策略可降低停机标定次数,提高系统可维护性。
输入:是运行中的多帧图像/轨迹与实时重投影误差统计。
输出:是“是否漂移”的告警与触发重标定后的更新参数(并给出设备重标定频率建议)。
2.3 深度学习在位姿估计中的应用
2.3.1 学习型特征点与描述子
在弱纹理、重复纹理、光照变化场景中,传统手工特征稳定性不足。学习型特征可显著提升匹配质量:
- 更强的光照与尺度鲁棒性。
- 更稳定的重复定位能力。
- 更高内点率,降低RANSAC试错成本。
典型做法是“学习特征 + 几何验证”:
- 网络提取关键点与描述子。
- 学习匹配器给出候选对应关系。
- 几何模型(E/F矩阵、PnP)筛内点并解位姿。
这种混合方案在工程上可解释性高,且便于定位错误来源。
输入:是两帧/多帧图像(可含时序)。
输出:是高质量匹配点对与置信度、筛选后的内点集合,以及最终位姿估计结果(E/F/PnP)。

2.3.2 学习型匹配与外点抑制
匹配环节是位姿稳定性的第一道关。深度学习可用于对匹配对进行上下文建模与置信度打分:
- 基于注意力机制建模全局一致性。
- 对重复结构和纹理混淆区域进行外点抑制。
- 输出匹配置信度,用于后续加权求解。
实际收益通常体现在:
- 同等帧数下更高可解率。
- 大基线或视角变化下更稳健。
- 低光和动态干扰条件下退化更慢。
输入:是候选匹配点对(及其局部特征/上下文信息)。
输出:是去外点后的高置信匹配与每对匹配权重,供后续加权位姿求解使用。

2.3.3 深度辅助位姿求解(Depth-aided Pose)
当仅靠2D匹配不稳定时,可引入学习深度先验提升位姿可观测性:
- 单目深度作为PnP中的3D锚点来源。
- 深度置信图用于剔除不可靠区域。
- 与光度一致性联合优化抑制尺度漂移。
适合场景:
- 纹理稀少、低重复结构环境。
- 长走廊、隧道、室内白墙等几何退化区域。
输入:是图像匹配结果 + 预测深度图/深度置信图(可再加光度误差)。
输出:是更稳定的相机位姿与尺度估计(同时剔除低置信深度区域)。

2.4 SLAM/SfM中的深度学习增强点
2.4.1 视觉里程计(VO)前端增强
可在跟踪前端引入学习模块:
- 关键点质量预测,优先使用高稳定性观测。
- 关键帧选择网络,降低冗余和漂移积累。
- 动态区域掩码,减少运动目标干扰。
输入:是连续图像帧(可含光流/语义信息)。
输出:是筛选后的高质量关键点、关键帧集合和动态掩码,用于更稳的前端跟踪
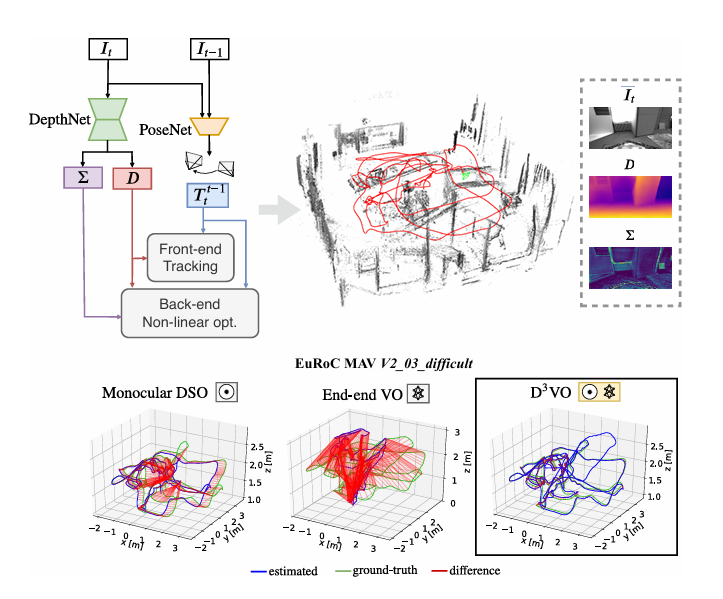
2.4.2 回环检测与重定位
学习型全局描述子可显著提升回环召回率:
- 在视角变化和光照变化下保持场景可识别性。
- 缩短重定位时间,增强长序列鲁棒性。
- 与图优化结合,改善全局一致性。
输入:是当前帧/关键帧图像及历史地图库(关键帧数据库)。
输出:是回环候选与重定位位姿(含相似度分数),并将约束送入图优化。
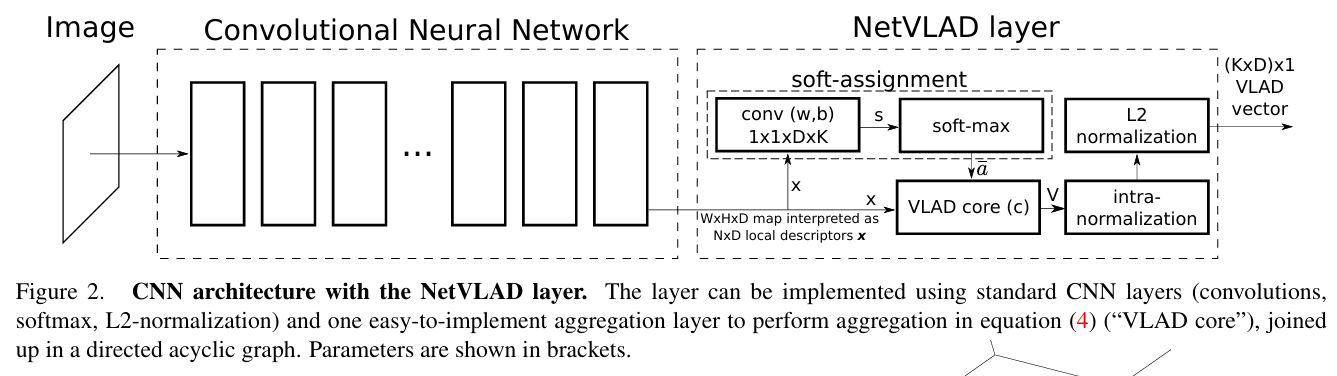
2.4.3 BA与图优化中的学习辅助
深度学习不直接替代优化器,而是提供更好的输入权重:
- 匹配边权重学习。
- 观测置信度建模。
- 不确定性估计用于鲁棒核自适应。
结果是优化过程更稳定、局部极值更少、收敛更快。
输入:是匹配边、观测残差和初始位姿/地图状态。
输出:是学习得到的边权重与不确定性(鲁棒核参数),供BA/图优化器加权求解并提升收敛稳定性
2.5 多传感器配准中的深度学习应用
当系统包含视觉、IMU、LiDAR或RGB-D时,跨模态配准成为关键难点。
2.5.1 视觉-IMU联合标定与对齐
- 学习时间同步偏差与噪声模型。
- 在高速运动中利用惯导稳定短时姿态。
- 通过联合优化抑制纯视觉漂移。
输入:相机图像序列 + IMU 时序数据(角速度/加速度)+ 时间戳(可含初始外参)
输出:相机-IMU 外参、时间偏移、噪声/偏置模型,以及融合后的稳定短时位姿
2.5.2 视觉-LiDAR配准
- 学习跨模态特征对齐(2D纹理与3D几何)。
- 对稀疏点云和遮挡场景增强配准鲁棒性。
- 提供初始变换供ICP/NDT精修。
输入:图像(2D)+ 点云(3D)+ 初始对应/先验变换(可选)
输出:跨模态对齐关系与初始变换 T_cam_lidar(R,t),供 ICP/NDT 精修
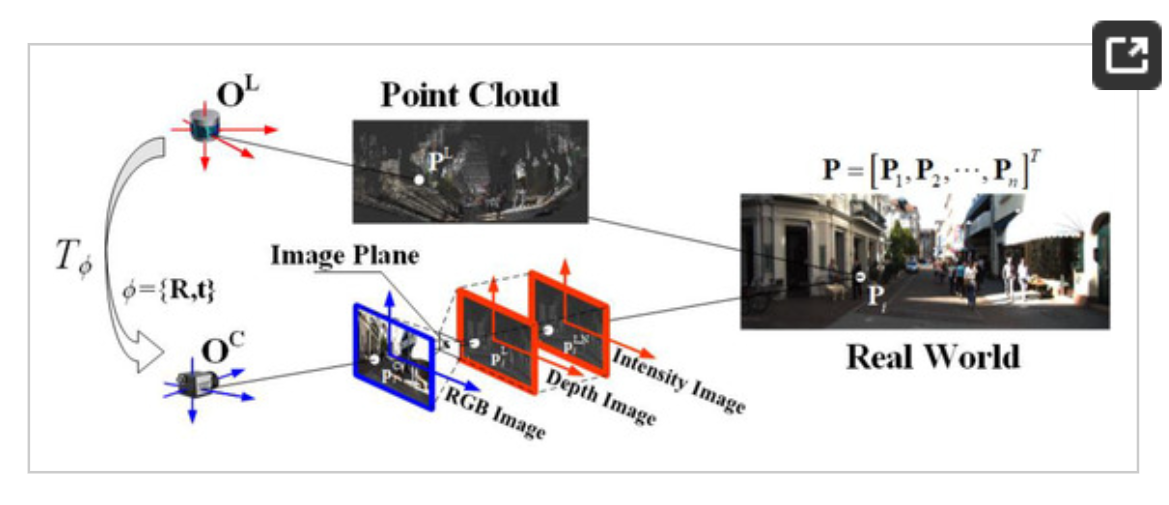
2.5.3 RGB-D与多相机系统对齐
- 深度置信度估计用于融合加权。
- 相机间外参偏移在线监测与修正。
- 大规模多相机阵列的自动一致性检查。
输入:RGB 图、深度图、多相机同步帧(可含历史外参与质量统计)
输出:融合权重(深度置信度)、更新后的相机间外参、阵列一致性检查结果/告警
2.6 常见错误模式与规避策略
问题1:把学习模型当作纯黑盒位姿解算器
- 表现:离线效果好,跨场景后位姿崩溃且难诊断。
- 规避:采用“学习匹配 + 几何求解”混合架构,保留可解释中间量。
问题2:忽略不确定性,所有匹配一视同仁
- 表现:少量错误匹配导致全局轨迹漂移。
- 规避:输出置信度并在PnP/BA中做加权优化。
问题3:动态区域未隔离
- 表现:车辆/行人主导特征,静态结构估计失真。
- 规避:前端加入动态分割与运动一致性过滤。
问题4:跨传感器初值差,后端难收敛
- 表现:ICP反复陷入局部最优。
- 规避:先用学习模型提供跨模态粗配准,再做几何精配准。
2.7 指标与评估建议
建议将评估分为“局部可解性、全局一致性、跨域鲁棒性”三类。
2.7.1 局部位姿质量
- 匹配内点率、重投影误差、PnP成功率。
- 短窗轨迹误差(RPE)。
- 跟踪中断频次与重定位时延。
2.7.2 全局一致性
- 绝对轨迹误差(ATE)。
- 回环后全局漂移残差。
- 稠密重建几何一致性(错层/重影比例)。
2.7.3 跨域鲁棒性
- 不同设备、光照、天气条件下性能波动。
- 动态干扰场景中的退化曲线。
- 长序列稳定性(公里级/小时级)表现。
若该环节优化有效,通常能在后端看到:重建完整度提升、几何噪声下降、失败率明显降低。
2.8 本节结论
相机标定、位姿估计与配准不是单点算法问题,而是整个重建Pipeline的几何底座。
深度学习在该环节最有效的用法是“增强鲁棒性和可解率”,而非完全取代几何约束。
实践中,推荐长期采用以下组合范式:
- 学习型特征与匹配提升前端观测质量;
- 几何求解与图优化保证物理一致性与可解释性;
- 不确定性建模贯穿匹配、求解和融合全流程。
当这三者协同,系统通常能同时获得更高精度、更强泛化和更低失败率,为后续深度估计与稠密重建提供稳定基础。
3. 深度估计与多视图几何
这一部分聚焦三维重建Pipeline里最核心的几何中层:把多视角图像转换为稳定、可融合的深度与几何关系。
写作上采用“用途驱动”方式:每个用途都给出你要求的 输入 / 输出,并附配图链接,便于快速理解与汇报展示。
3.1 用途A:单目深度先验生成(给位姿与MVS提供初始几何)
- 输入:RGB图(单帧或短时序)、可选历史外参、可选质量统计(清晰度/曝光评分)。
- 输出:初始深度图、深度置信度图(可转成融合权重)、尺度一致性评分。
说明
单目深度本身存在尺度歧义,但在工程中非常有价值:可作为后续多视图深度求解的初值,也可在弱纹理区域提供“可观测性补偿”。
常见做法是使用自监督深度网络产出 depth + confidence,并把低置信区域交给后续多视图几何再修正。
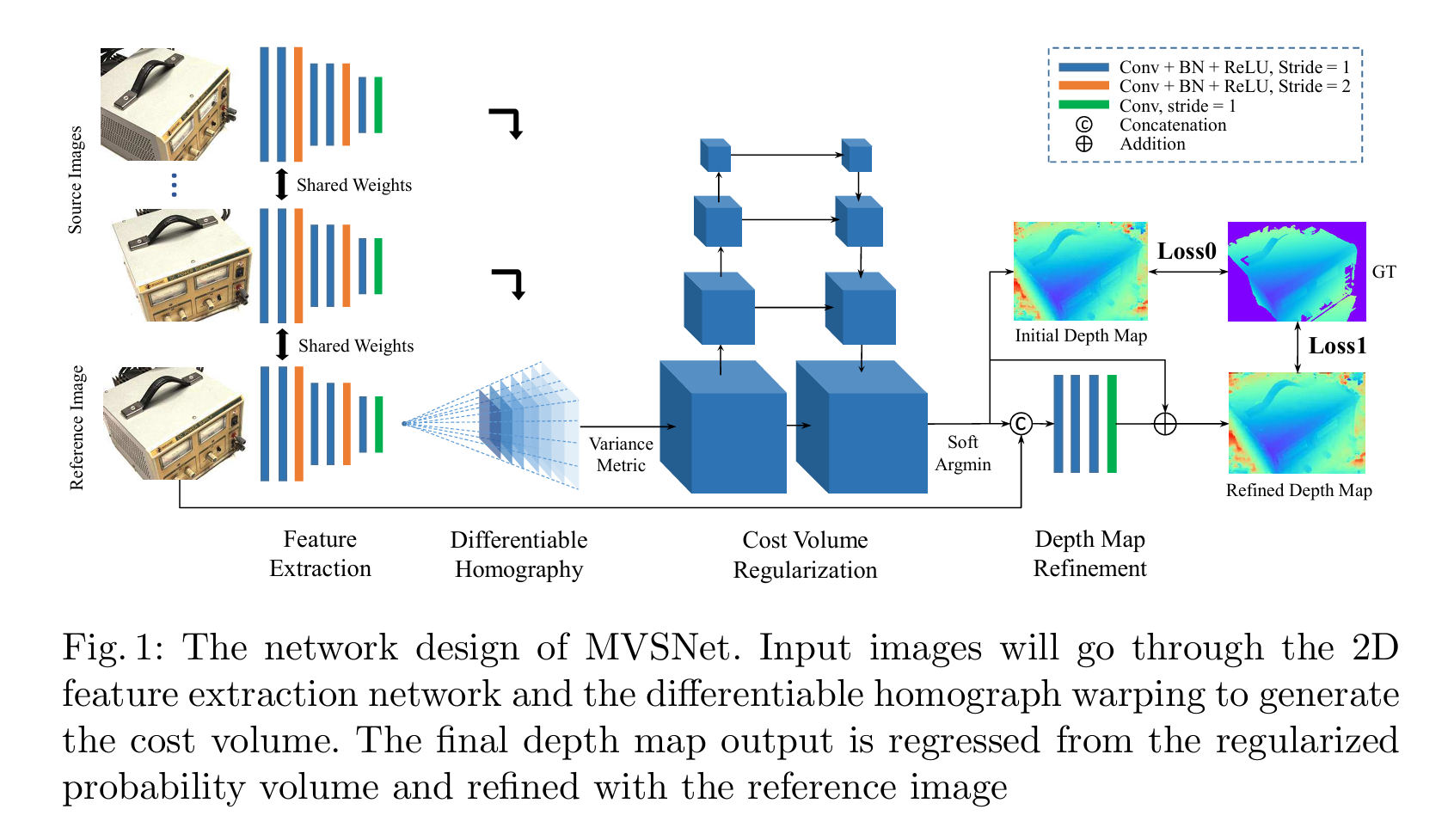
3.2 用途B:多视图深度推断(MVS主干)
- 输入:多相机同步帧(含内外参初值)、参考帧RGB图、候选源视图集合、可选历史外参与质量统计。
- 输出:参考帧深度图、像素级概率/置信度图(融合权重)、可见性掩码。
说明
这是学习型MVS的核心环节:通过可微单应变换构造代价体(Cost Volume),再做3D正则化,得到深度与概率图。
概率图可以直接转为融合阶段的权重,低概率区域会被抑制,减少伪深度污染。
3.3 用途C:多视图几何一致性校验(剔除伪匹配与伪深度)
- 输入:参考帧深度图、源视图深度图、相机位姿(当前估计)、重投影误差统计。
- 输出:几何一致性分数、点级/像素级有效性掩码、更新后的融合权重。
说明
深度估计并不等于“可直接融合”。必须通过前后向重投影、视角一致性、遮挡一致性做过滤。
这一步是控制“毛刺点云、悬浮面片、边缘错层”的关键,通常会对后续网格质量产生决定性影响。
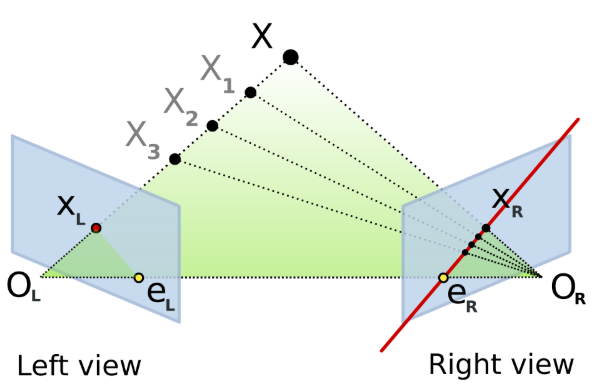
3.4 用途D:深度置信度建模与融合权重预测
- 输入:RGB图、深度图、法线/梯度信息、历史帧稳定性统计(可选)。
- 输出:融合权重(深度置信度)、不确定性热力图、可选“拒绝融合”掩码。
说明
工程里最常见问题是“平均融合把错误也平均进去了”。
正确做法是先预测深度不确定性,再以学习权重进行加权融合;高置信区域主导表面,低置信区域延后决策或交由更多视角补证。
3.5 用途E:相机间外参在线微调(阵列长期运行必需)
- 输入:多相机同步帧(可含历史外参与质量统计)、跨视角匹配对、重投影残差序列。
- 输出:更新后的相机间外参、外参漂移趋势、校正可信度。
说明
多相机系统在长期运行中会出现轻微机械漂移或热漂移。
可用学习匹配 + 几何优化做在线微调:学习模块提供更稳健对应关系,几何优化保证参数物理合理。
3.6 用途F:阵列一致性检查与告警(运维与质量闭环)
- 输入:多相机同步帧、当前外参、深度置信度统计、历史告警日志。
- 输出:阵列一致性检查结果/告警、异常相机列表、建议处理动作(重标定/降权/剔除)。
说明
这一用途直接对应场景化表达:不仅要“算出来”,还要“可监控、可报警、可运维”。
常见告警规则包括:重投影误差突增、跨相机深度断层、某路相机长期低置信度等。

3.7 用途G:时序深度稳定化(视频重建去抖与抗闪烁)
- 输入:连续RGB帧、历史深度图、历史外参、帧质量统计(模糊/曝光/动态比例)。
- 输出:时序平滑后的深度序列、帧间一致性分数、时序融合权重。
说明
视频场景中,单帧深度“看起来正确”不代表时序稳定。
深度学习可结合时序先验(光流、时序Transformer、循环状态)抑制闪烁与局部跳变,提升最终重建的连续表面质量。
3.8 用途H:神经表示中的深度几何约束(NeRF/3DGS阶段)
- 输入:多视角RGB图、相机位姿、可选深度先验图/深度置信度图。
- 输出:几何一致的辐射场参数、可渲染深度图、可用于融合的置信信息。
说明
NeRF/3DGS强调新视角合成,但如果缺少深度几何约束,容易出现漂浮结构与几何歧义。
将深度图及其置信度纳入训练损失,可显著提升收敛速度与几何真实性。
3.10 小结(第3章结论)
“深度估计与多视图几何”不是单个算法点,而是连接前端位姿与后端融合的关键枢纽层。
在实际项目中,建议优先建设三项能力:
深度 + 置信度联合输出(不要只要深度值)。- 几何一致性过滤与加权融合(不要直接平均)。
- 外参在线微调 + 阵列一致性告警(保证长期稳定运行)。
做到这三点,通常可以同时提升重建精度、系统稳定性和可运维性。
4. 稠密重建与三维表示生成
这一部分关注三维重建Pipeline中“落地成形”的环节:把多视图深度、位姿和置信信息,转化为可使用的三维表示(点云、网格、隐式场、神经表示等)。
4.1 用途A:深度图融合为稠密点云(Dense Fusion)
- 输入:多视图RGB图、深度图、相机位姿、深度置信度(融合权重)、可见性掩码。
- 输出:融合点云(含点置信度)、异常点剔除结果、局部完整性统计。
说明
这是从“每帧深度”走向“统一三维几何”的第一步。
关键在于:不是简单叠加,而是利用深度置信度做加权融合,并通过重投影一致性过滤掉漂浮点与外点。

4.2 用途B:点云去噪、补全与上采样(Point-level Enhancement)
- 输入:原始融合点云、点置信度、RGB颜色/法线信息、可选历史重建结果。
- 输出:去噪点云、补全点云、上采样点云、点级质量评分。
说明
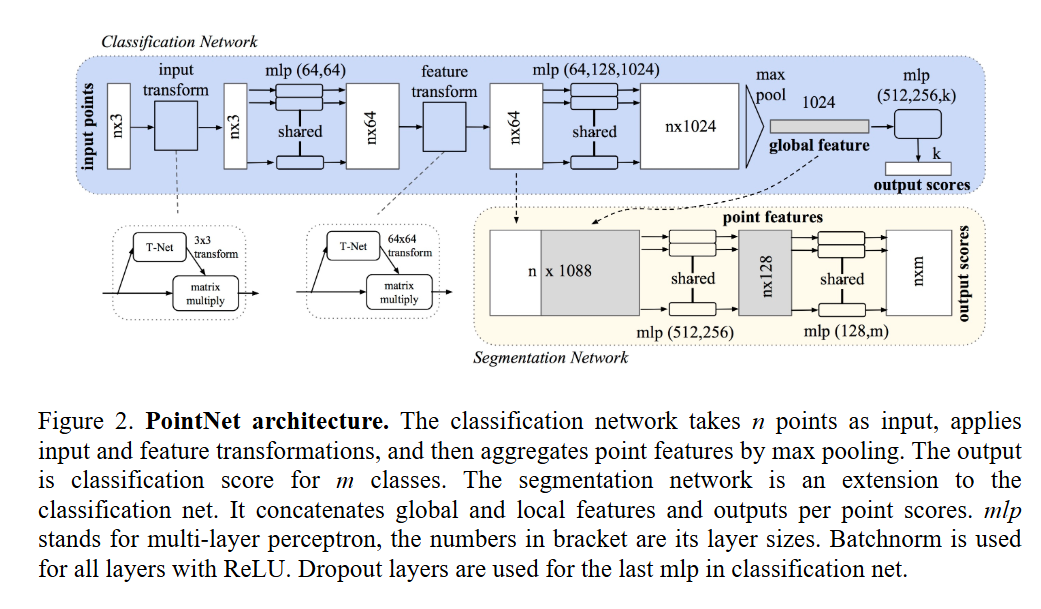
融合点云常见问题是“噪声多、孔洞多、边缘破碎”。
深度学习可通过点云补全网络与局部几何先验提升完整性,特别适合弱纹理区域和遮挡区域恢复。
4.3 用途C:点云到网格重建(Surface Meshing)
- 输入:增强后点云、法线估计、点置信度、可选语义边界信息。
- 输出:三角网格(Mesh)、孔洞填补结果、拓扑一致性检查报告。
说明
网格是最常见的工程交付形式(CAD、仿真、渲染、打印都依赖网格)。
深度学习可辅助边界恢复和孔洞修复,但最终通常仍结合传统几何算法(Poisson、Delaunay、Marching Cubes)保证拓扑可控。

4.4 用途D:TSDF/体素融合(可实时增量建图)
- 输入:RGB-D帧流或多视图深度、相机位姿、体素网格配置、深度置信度。
- 输出:TSDF体(或体素场)、增量网格结果、体素置信度地图。
说明
TSDF融合是工业和机器人中非常实用的“稳健方案”:可增量更新、可实时、抗噪能力强。
深度学习常用于预测每帧深度置信度、优化融合权重、补洞与边界锐化。

4.5 用途E:隐式表示生成(Occupancy / SDF)
- 输入:多视图RGB图、深度先验、相机位姿、采样点坐标、可选法线约束。
- 输出:隐式场参数(Occupancy或SDF)、可提取网格、几何误差统计。
说明
隐式表示适合高质量连续表面建模,能表达复杂拓扑并减少离散网格伪影。
常见流程是先学习场函数,再通过Marching Cubes提取可用网格。
4.6 用途F:神经辐射场与3DGS表示生成(NeRF/GS)
- 输入:多视图RGB图、相机位姿、可选深度图与深度置信度、可选语义先验。
- 输出:NeRF或3D Gaussian Splatting参数、可渲染新视角、可导出几何(深度/点云/网格)。
说明
这类表示在“视觉真实感”上表现突出,适合数字内容生产和新视角渲染。
若要用于工程几何任务,通常需要引入深度监督与几何一致性约束,避免外观好但几何漂移。
4.7 用途G:多表示协同转换(Point ↔ Mesh ↔ Implicit ↔ Neural)
- 输入:已有三维表示(点云/网格/隐式场/神经表示)、质量评分、目标应用约束(渲染/仿真/检测)。
- 输出:目标表示格式、转换误差报告、应用适配版本(轻量/高保真)。
说明
工程中没有“唯一最佳表示”,而是“按任务切换表示”:
- 视觉渲染偏NeRF/3DGS;
- 工业测量偏网格/点云;
- 优化学习偏隐式场。
深度学习可在表示转换时补偿细节与抑制信息损失。
4.8 用途H:阵列级一致性重建与在线告警
- 输入:多相机同步帧、历史外参与质量统计、深度置信度图、跨相机重投影误差。
- 输出:融合权重(深度置信度)更新、更新后的相机间外参、阵列一致性检查结果/告警。
说明
这一步把第3章的几何中层能力,真正落到第4章的“最终表示质量”上:
当某路相机偏移或质量下降时,系统自动降权、触发外参微调并告警,避免错误几何进入最终模型。
4.9 小结
稠密重建与三维表示生成的关键,不在于“选哪个表示最先进”,而在于“是否构建了稳定的表示生产链路”:
- 深度与置信度联合驱动融合(先控制错误传播)。
- 按任务选择最合适表示(点云/网格/隐式/神经场)。
- 阵列一致性和在线告警贯穿全流程(保证长期可用)。
当这三点同时满足时,系统才能从“能重建”走向“能交付、能维护、能规模化部署”。
5. 纹理/材质/外观恢复
几何重建解决的是“形状对不对”,而纹理/材质/外观恢复解决的是“看起来像不像、渲染是否真实、下游能否直接用”。
5.1 用途A:多视图纹理融合(Texture Blending)
- 输入:三维网格或点云、多视图RGB图、相机位姿、可见性与遮挡信息、图像质量统计。
- 输出:纹理贴图(UV纹理或点颜色)、视角加权融合结果、纹理接缝质量报告。
说明
多视图纹理融合的关键是“选对来源视角并平滑拼接”。
深度学习可用于预测每个视角的纹理可信度(清晰度、反光、曝光一致性),在融合时动态赋权,减少缝合痕迹与颜色跳变。

5.2 用途B:纹理超分与细节增强(Super-Resolution for Texture)
- 输入:低分辨率纹理图、原始多视图RGB图、几何边界信息(法线/深度边缘)。
- 输出:高分辨率纹理图、细节增强结果、边缘保真度评分。
说明
在移动端采集或远距离采集中,纹理分辨率经常不足。
可用超分网络恢复高频细节,同时结合几何边界约束,避免“看起来更清晰但结构错位”的伪细节。
5.3 用途C:光照分解与重光照一致性(Intrinsic Decomposition)
- 输入:RGB图、多视图位姿、几何先验(法线/深度)、可选环境光信息。
- 输出:反照率(Albedo)、阴影/光照分量、重光照后外观一致性结果。
说明
同一物体在不同视角可能受光照影响明显,直接纹理融合会产生颜色不一致。
通过分解“材质本色”和“光照影响”,可获得跨视角一致的外观,后续在渲染和编辑中更稳定。
5.4 用途D:反光/透明材质恢复(Specular & Transparent Handling)
- 输入:多视图RGB图、深度图、偏振或多曝光信息(可选)、历史质量统计。
- 输出:反光区域修正纹理、透明区域外观估计、高风险区域告警图。
说明
反光与透明材质是外观恢复难点:镜面高光会被误当作纹理,玻璃区域常导致纹理错贴。
深度学习可先检测材质类型,再采用材质感知融合策略,降低伪纹理与“漂浮反光”现象。
5.5 用途E:材质参数估计(PBR参数恢复)
- 输入:RGB图、几何模型(法线/粗糙几何)、多视角观测、可选光照先验。
- 输出:PBR材质贴图(Albedo、Roughness、Metallic、Normal)、材质置信度图。
说明
对游戏、数字孪生和工业仿真来说,仅有“颜色纹理”不够,还需要可物理渲染的材质参数。
深度学习可以从多视角外观反推材质属性,输出可直接用于现代渲染引擎的PBR贴图。
配图链接

5.6 用途F:视角相关外观建模(View-dependent Appearance)
- 输入:多视图RGB图、相机位姿、可选深度先验与法线。
- 输出:视角相关外观函数、新视角渲染结果、外观一致性评分。
说明
某些材质(如金属、车漆)会随观察角度变化。
如果只用“静态纹理贴图”表达,渲染会失真。神经渲染方法(NeRF家族)可学习视角相关外观,在真实感上优势明显。
5.7 小结
纹理/材质/外观恢复的核心不是“加一层贴图”,而是建立一套可解释、可评估、可运维的外观生产链:
- 多视图纹理融合要以质量权重驱动,避免接缝和色偏。
- 材质恢复要从“颜色贴图”升级到“可渲染参数贴图(PBR)”。
当几何质量与外观质量同时达标,三维重建结果才真正具备产品化价值。
6. 动态场景与时序一致性
静态场景重建的核心是空间一致性,而动态场景重建的核心是“空间一致性 + 时间一致性”。
在真实应用中(自动驾驶、机器人巡检、移动端扫描、人体重建),动态目标与时间漂移是导致重建失败的主要原因之一。
6.1 用途A:动态区域检测与静动态解耦
- 输入:连续RGB帧、可选深度图/光流、历史外参与质量统计。
- 输出:动态区域掩码、静态背景掩码、动态目标列表与置信度。
说明
动态目标(人、车、摆动物体)会破坏静态几何假设,导致位姿漂移和重影。
先做静动态解耦,再分别处理,是动态场景重建的基础动作。
6.2 用途B:时序位姿稳定与漂移抑制(Temporal Pose Stabilization)
- 输入:多帧特征匹配结果、IMU/里程计信息(可选)、历史外参、动态掩码。
- 输出:时序平滑位姿轨迹、漂移估计曲线、异常跳变告警。
说明
动态场景下,逐帧位姿常出现“短时抖动 + 长期漂移”。
深度学习可学习轨迹先验与不确定性,配合图优化提升全局一致性。
6.3 用途C:时序深度一致性约束(Depth Temporal Consistency)
- 输入:连续RGB图、单帧/多视图深度图、历史深度图、历史外参与质量统计。
- 输出:时序一致深度图、深度置信度更新(融合权重)、深度闪烁告警图。
说明
视频重建常见问题不是“某一帧错”,而是“帧间忽高忽低的深度闪烁”。
通过时序一致性损失、光流引导和短时记忆模型,可显著提升深度稳定性。
6.4 用途D:动态目标的4D重建(3D + Time)
- 输入:目标相关多视图视频帧、相机位姿、可选人体/物体先验模型。
- 输出:时变几何序列(4D表示)、动态轨迹、逐时刻外观结果。
说明
对人体动作、工业机械臂、交通参与体等,需要重建“随时间变化的形状”。
4D重建不仅要还原几何,还要保证时间连续与拓扑稳定。

6.6 用途F:时序融合权重与关键帧调度
- 输入:连续RGB/深度帧、每帧质量评分、历史外参与误差统计、动态占比。
- 输出:时序融合权重(深度置信度)、关键帧更新策略、帧级保留/丢弃决策。
说明
在线重建系统中,不是每帧都应等权参与融合。
应根据质量、动态程度、几何增益动态分配权重,保证“少而有效”的时序融合。
6.7 小结(第6章结论)
动态场景重建的难点从来不只是“几何精度”,而是“几何 + 时间 + 系统稳定性”的联合约束。
工程上建议优先落地以下三项能力:
- 静动态解耦 + 时序深度一致性(先控制误差扩散)。
- 位姿漂移抑制 + 融合权重调度(保证长期稳定)。
当这三项能力建立后,系统才能在真实动态环境中持续输出可用的三维结果。
7. 语义增强重建
传统三维重建通常只关注几何与外观,但在工程应用中,还需要模型具备“语义可理解性”:哪里是墙、哪里是路、哪里是设备、哪里是可交互对象。
语义增强重建的目标,是让重建结果不仅可视化,还能被检索、分析、编辑、决策系统直接使用。
7.1 用途A:2D语义分割引导3D重建
- 输入:多视图RGB图、2D语义分割结果、相机位姿、深度图(可选)。
- 输出:带语义标签的3D点云/网格、类别置信度图、语义覆盖率统计。
说明
先在2D做语义分割,再通过重投影映射到3D,是最常见、最稳健的语义增强路径。
其优势是可复用成熟2D模型,快速获得场景级语义结构。

7.2 用途B:实例级重建(对象分离与对象级建模)
- 输入:多视图RGB图、实例分割结果、相机位姿、深度图、历史外参与质量统计(可选)。
- 输出:对象级3D实例(每个物体独立ID)、实例边界与置信度、对象级告警(遮挡/缺失)。
说明
语义类别(如“车”)不足以支持下游任务,很多应用需要实例粒度(“第3辆车”)。
实例级重建可支持对象追踪、资产管理、机器人抓取和工业盘点。

7.3 用途C:语义约束的深度与几何优化
- 输入:RGB图、深度图、语义标签、相机位姿、重投影误差统计。
- 输出:语义一致深度图、融合权重(深度置信度)更新、几何异常区域标记。
说明
语义可以作为几何先验:
- “墙面/地面”应具备连续和平面倾向;
- “天空/玻璃反射”深度可信度应降低。
通过语义-几何联合优化,可减少重建噪声并提高结构可解释性。
7.4 用途D:语义地图与几何地图联合构建
- 输入:多相机同步帧、位姿轨迹、语义分割结果、深度图、历史外参与质量统计。
- 输出:语义地图(类别/实例)、几何地图(点云/网格/体素)、联合一致性检查结果/告警。
说明
在机器人和自动驾驶系统中,真正有价值的是“语义+几何”联合地图,而非纯几何模型。
联合地图可同时服务导航、避障、巡检、目标检索和路径规划。

7.5 用途E:语义驱动的可编辑重建
- 输入:带语义标签的3D模型、对象实例ID、材质/纹理信息、用户编辑指令。
- 输出:可编辑语义3D资产(按类别/实例操作)、编辑日志、区域一致性告警。
说明
语义增强的最大工程价值之一是“可编辑”:
例如只替换墙体材质、只删除某类障碍物、只导出某类设备。
这使三维重建从“展示结果”转向“生产工具”。
7.6 用途F:开放词汇语义增强(Open-vocabulary 3D)
- 输入:多视图RGB图、文本类别提示(prompt)、相机位姿、可选深度图。
- 输出:开放词汇语义标签、语义检索结果、未知类别告警。
说明
封闭类别语义模型在新场景会失效。
开放词汇方案(视觉-语言模型)允许用自然语言扩展类别,提升跨域泛化和部署灵活性。
7.7 用途G:语义时序一致性与跨帧ID维护
- 输入:连续多帧语义分割结果、实例跟踪结果、历史外参与质量统计。
- 输出:时序一致语义标签、稳定实例ID轨迹、语义漂移告警。
说明
视频重建中经常出现“同一对象跨帧标签跳变”。
语义时序一致性模块可通过时序关联和轨迹约束稳定标签,减少后续对象级分析误差。
7.8 用途H:语义质量评估与系统告警闭环
- 输入:语义3D模型、融合权重历史、更新后的相机间外参、阵列一致性日志。
- 输出:语义完整率/准确率指标、类别级异常告警、重采与重建建议。
说明
语义增强落地后必须建立质量闭环:
- 哪些类别稳定;
- 哪些类别易误检;
- 哪些相机位置导致语义盲区。
该模块直接支持数据回流与模型迭代。
7.9 小结
语义增强重建的本质,是让三维模型从“几何资产”升级为“可理解、可操作、可决策的数据资产”。
工程上建议优先建设三项核心能力:
- 2D语义到3D映射(快速建立语义底座)。
- 语义-几何联合优化(提升稳定性与可解释性)。
- 语义质量告警与数据回流(保障长期演进)。
当语义能力融入重建Pipeline后,系统价值会从“可视化展示”扩展到“自动化分析与业务闭环”。
8. 后处理与模型优化
前面章节解决的是“如何得到三维结果”,本章解决的是“如何把结果变成稳定、轻量、可运行的产品资产”。
后处理与模型优化在工程里往往决定最终交付质量:没有这一层,常见问题是模型很重、噪声多、实时性差、跨设备表现不稳定。
8.1 用途A:几何去噪与离群点清理(Geometry Cleanup)
- 输入:原始点云/网格、点级置信度、深度融合权重、可选历史重建结果。
- 输出:去噪后的点云/网格、离群点报告、局部质量热力图。
说明
重建结果常带有漂浮点、边缘毛刺、局部噪声。
可结合统计滤波、法线一致性约束和学习型去噪网络做清理,减少后续网格修复压力。

8.2 用途B:孔洞填补与表面修复(Hole Filling & Surface Repair)
- 输入:不完整网格/点云、法线信息、纹理边界信息、语义标签(可选)。
- 输出:补洞后的网格、边界连续性评分、修复区域标注。
说明
遮挡、弱纹理和反光会造成几何缺失。
后处理阶段应优先修复“结构关键区域”(边缘、连接面、接触面),避免拓扑断裂影响下游应用。
8.3 用途C:网格简化与LOD生成(面向实时渲染)
- 输入:高精网格、目标平台约束(帧率/显存/带宽)、可选语义重要性权重。
- 输出:多级LOD网格、简化误差报告、关键区域保真度评估。
说明
原始高精网格通常无法直接部署到实时系统。
应基于应用目标生成多级细节(LOD),并保证语义关键区域(如设备边缘、可交互区域)优先保留精度。
8.4 小结(第8章结论)
后处理与模型优化是三维重建从研究原型走向产品交付的关键一跳。
工程上建议优先建立三条能力链:
- 几何清理与修复链(去噪、补洞、LOD)。
- 模型轻量与部署链(蒸馏、量化)。
总结
深度学习在三维重建中的作用,已经从“单点提精度”发展为“全链路增强”。在任务入口阶段,它用于模态适配与方案选型(单目、多视图、视频、RGB-D、LiDAR)以确定可观测性上限;在数据采集阶段,用于图像质量评估、关键帧筛选、动态干扰检测和主动采集,提升输入数据可用性。进入几何前端后,深度学习主要增强标定、特征匹配、外点抑制、位姿估计与跨传感器配准,并通过置信度建模提高SfM/SLAM可解率与鲁棒性。
在深度估计与多视图几何阶段,其核心贡献是学习型MVS、深度不确定性预测与几何一致性校验,使“深度+置信度”成为融合前的标准输出。到稠密重建与表示生成阶段,深度学习用于点云融合加权、去噪补全、网格修复、隐式场建模及NeRF/3DGS表示学习,支撑从几何重建到高保真渲染的多目标需求。外观恢复阶段则聚焦纹理融合、超分增强、光照分解、反光透明材质处理与PBR参数估计,实现“形状正确”向“观感真实”升级。面对动态场景,深度学习通过静动态解耦、时序深度一致性、漂移抑制与4D建模保障时空连续。结合语义增强后,系统可实现2D到3D语义映射、实例级重建、语义-几何联合优化与开放词汇检索,使重建结果可检索、可编辑、可决策。最后在后处理与部署优化中,深度学习用于几何清理、补洞、LOD生成及模型压缩加速,推动成果走向可部署、可维护、可规模化落地。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
点击排行
本站推荐
