首页 > 基础资料 博客日记
NVIDIA H200/H20 DeepSeek-V4-Pro 部署指南、压测性能与稳定性调优建议
2026-04-28 10:30:02基础资料围观1次
随着 DeepSeek 正式发布 DeepSeek-V4 系列,大模型的工程边界再次被明显推高。该系列基于 MoE 架构,提供了 DeepSeek-V4-Flash 284B 和 DeepSeek-V4-Pro 1.6T 两种规格,同时在推理阶段仅激活数十亿参数,在性能与成本之间取得了新的平衡。配合百万级上下文窗口与全新的注意力优化机制,其在长文本理解、复杂推理以及智能体任务中的表现,已经开始逼近甚至挑战当前主流闭源模型。
从架构设计来看,DeepSeek-V4 不只是简单的参数扩展,而是在多个关键路径上进行了系统性优化。例如混合注意力机制(CSA+HCA)显著降低长上下文推理成本,mHC 结构强化深层网络的稳定性,而 Muon 优化器则提升了训练效率与收敛表现。这些优化技术使得其在长上下文与复杂推理场景中具备更高的性价比。
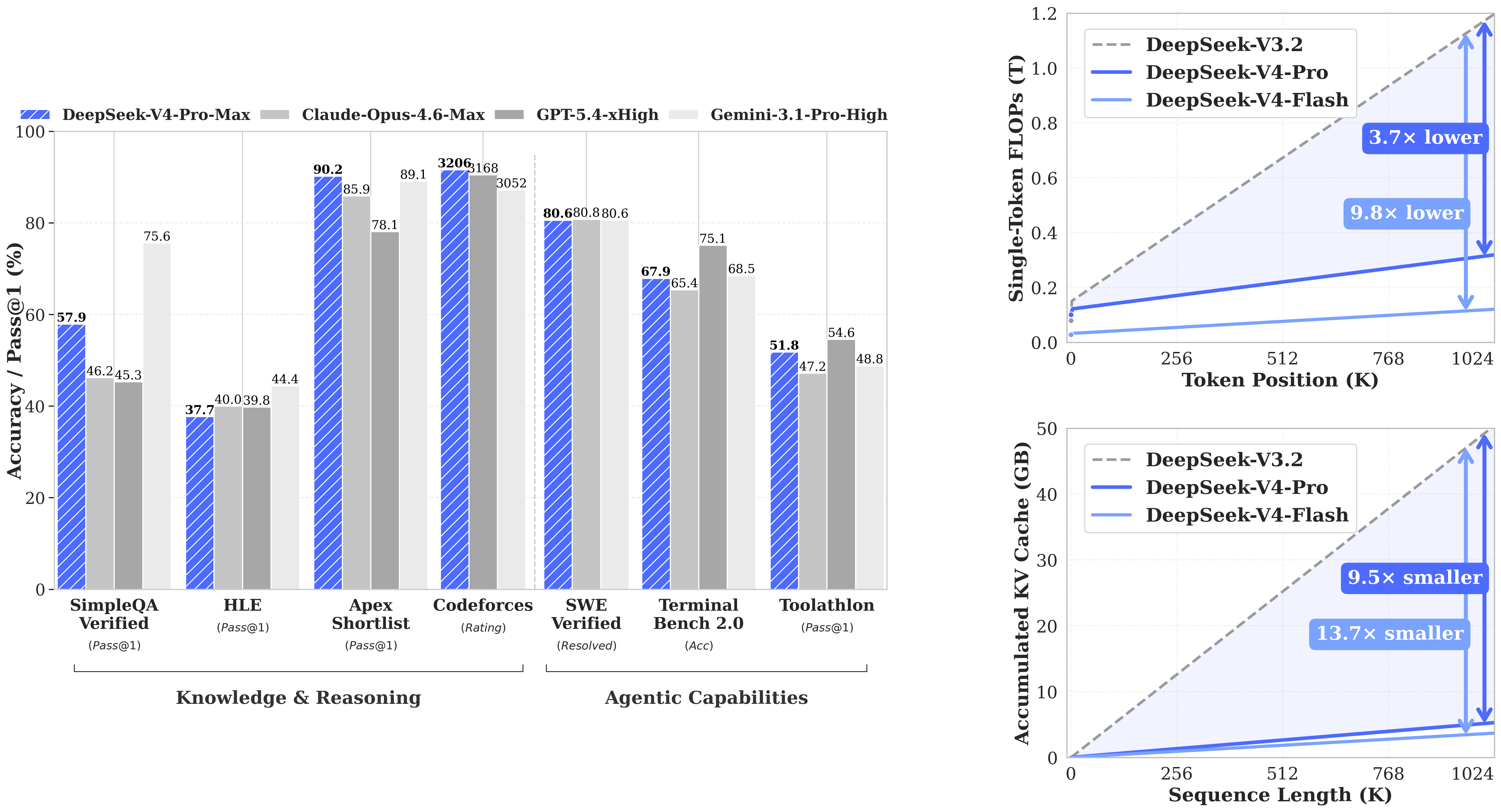
另一方面,这类超大规模 MoE 模型对对底层硬件与推理引擎的适配能力提出了更高要求,DeepSeek-V4 的稳定运行与性能释放,仍然需要从硬件厂商到推理引擎的持续优化与协同改进。本文基于 GPUStack,提供在单台 NVIDIA H200/H20 141GB 环境部署 DeepSeek-V4 的实践教程,并给出实际压测性能表现数据,以及针对压测表现提供的稳定性配置建议,供参考。
GPUStack 安装与集群初始化
GPUStack 是一个开源 GPU 集群管理与 AI 模型服务平台,旨在高效部署 AI 模型。它可以配置并编排多种推理引擎——如 vLLM、SGLang、TensorRT-LLM,甚至自定义引擎——以在 GPU 集群上实现最佳性能。核心功能包括多异构 GPU 集群池化调度、可插拔推理引擎架构、Day 0 模型支持、性能优化配置(低延迟/高吞吐)、以及企业级运维能力,如故障恢复、负载均衡、监控与权限管理。
GPUStack 可以帮助我们高效地管理 vLLM、SGLang 等推理引擎,并推动模型从部署走向企业生产落地运营。在开始部署 DeepSeek V4 之前,首先完成 GPUStack 控制面的安装,并将 NVIDIA GPU 节点纳入管理。
准备容器环境
GPUStack 以容器方式运行,因此需要提前准备好容器运行环境(如 Docker、Podman 或 Kubernetes)。本文以 Docker 为例进行说明。
在各节点上安装 Docker,确保服务已正常启动:
docker info
启动 GPUStack Server
GPUStack Server 无需依赖 GPU,可运行在普通 CPU 节点上,也可运行在 GPU 节点。本文以八卡 NVIDIA H200 141GB 为实验环境,在该节点上启动 GPUStack Server 容器:
sudo docker run -d --name gpustack \
--restart unless-stopped \
-p 80:80 \
--volume gpustack-data:/var/lib/gpustack \
swr.cn-south-1.myhuaweicloud.com/gpustack/gpustack:v2.1.2 \
--debug --bootstrap-password GPUStack@123
关键参数说明:
- -p 80:80:用于对外暴露 Web 控制台端口;如需修改为其他端口(例如 9999),可调整为 -p 9999:80。
- --volume:持久化平台数据(包括模型服务、计量数据、API Key 等)
- --bootstrap-password:初始化 admin 用户密码
- --debug:开启调试日志,便于排查问题
容器启动后,可以通过日志确认服务是否正常运行:
docker logs -f gpustack
访问控制台并初始化
打开浏览器访问:http://<Server 主机 IP>:80
使用默认账号登录:
- 用户名:admin
- 密码:GPUStack@123
登录后,首先创建一个 Docker 类型的集群,用于统一管理后续接入的 GPU 节点。
添加 NVIDIA GPU Worker 节点
在集群创建完成后,可以接入 NVIDIA GPU 节点。
在添加节点之前,先完成基础环境检查。
(1)驱动版本检查
在目标节点上执行以下命令:
nvidia-smi
该命令会显示当前安装的 NVIDIA 驱动版本。请确认驱动版本 ≥ 580,以保证对 DeepSeek V4 模型的兼容性和稳定性。
(2)Nvidia Container Toolkit 检查
执行以下命令检查 Docker 是否正确配置了 Nvidia Container Toolkit:
sudo docker info 2>/dev/null | grep -q "Runtime.*nvidia" && echo "Nvidia Container Toolkit OK" || (echo "Nvidia Container Toolkit not configured"; exit 1)
- 该命令会从
docker info输出中查找是否存在nvidia运行时配置。 - 如果输出 "Nvidia Container Toolkit OK",说明 Docker 已正确配置,可在容器中访问 GPU。
- 如果输出 "Nvidia Container Toolkit not configured",则说明未正确配置,需要安装并启用 Nvidia Container Toolkit,否则推理容器无法使用 GPU 资源。
(3)接入 Worker 节点
在 GPUStack 控制台中,选择添加节点(Worker),并复制系统生成的接入命令,在目标节点执行。
该命令本质上会启动一个 Worker 容器,并自动注册到 Server。
(4)验证 Worker 状态
节点接入后,可以在节点上查看容器日志:
docker logs -f gpustack-worker
同时,在 GPUStack 控制台中也可以看到节点状态是否为 Ready。
至此,GPUStack 的控制面已成功部署,NVIDIA GPU 节点也顺利接入集群,并能够正常采集设备名称、索引、厂商信息、温度、利用率及显存使用等指标。接下来即可在该环境中部署具体的推理服务。
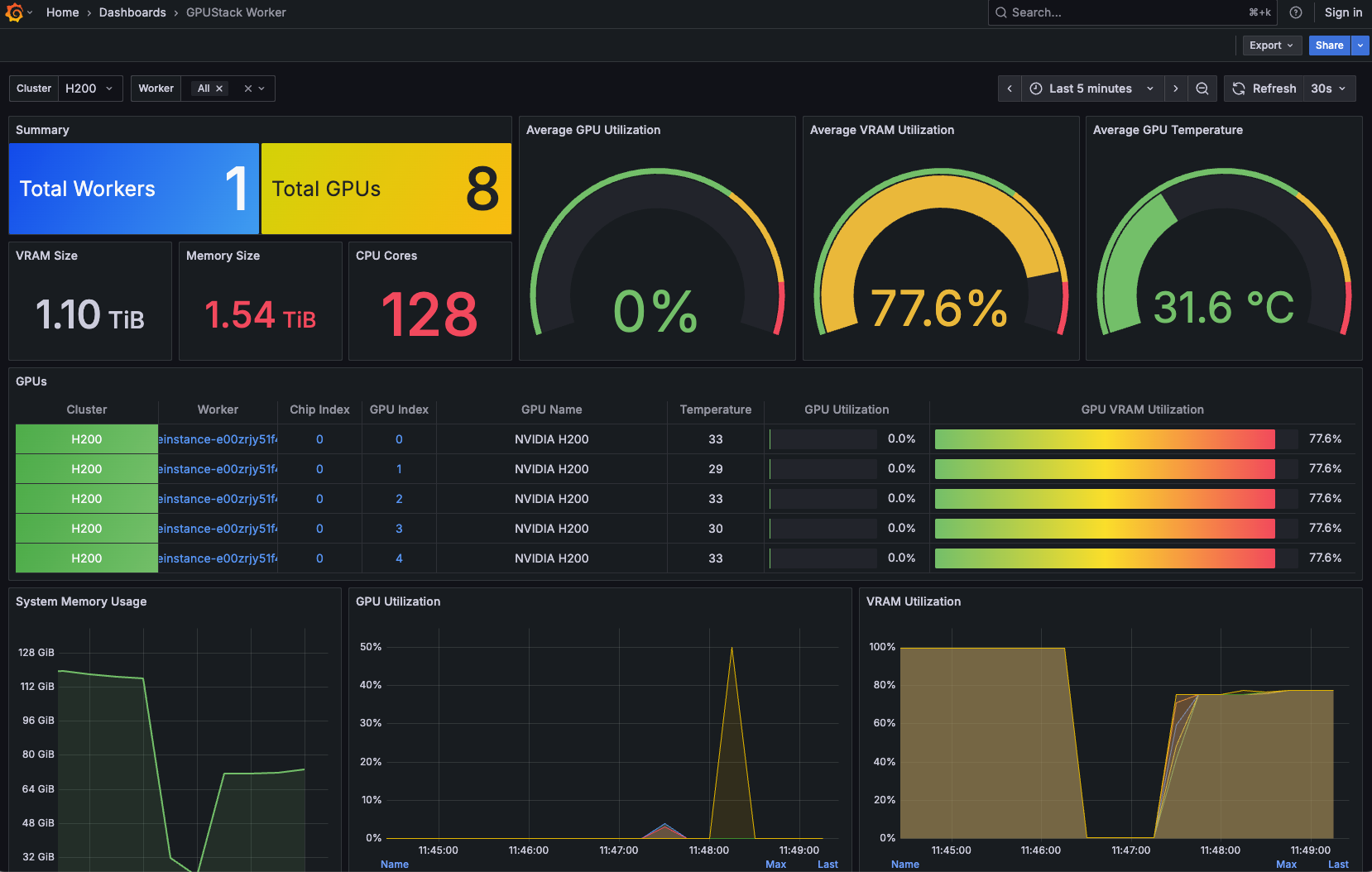
GPU 资源监控数据
添加自定义 vLLM 版本
GPUStack 支持可插拔的推理引擎架构,允许自定义推理后端及其版本,用于引入 GPUStack 未内置的 vLLM / SGLang / MindIE 版本,或接入其他自定义推理引擎镜像。
为了部署 DeepSeek V4 模型,需要添加 vLLM 最新发布的支持 DeepSeek V4 构建的 vllm/vllm-openai:v0.20.0-cu130 版本。
vLLM
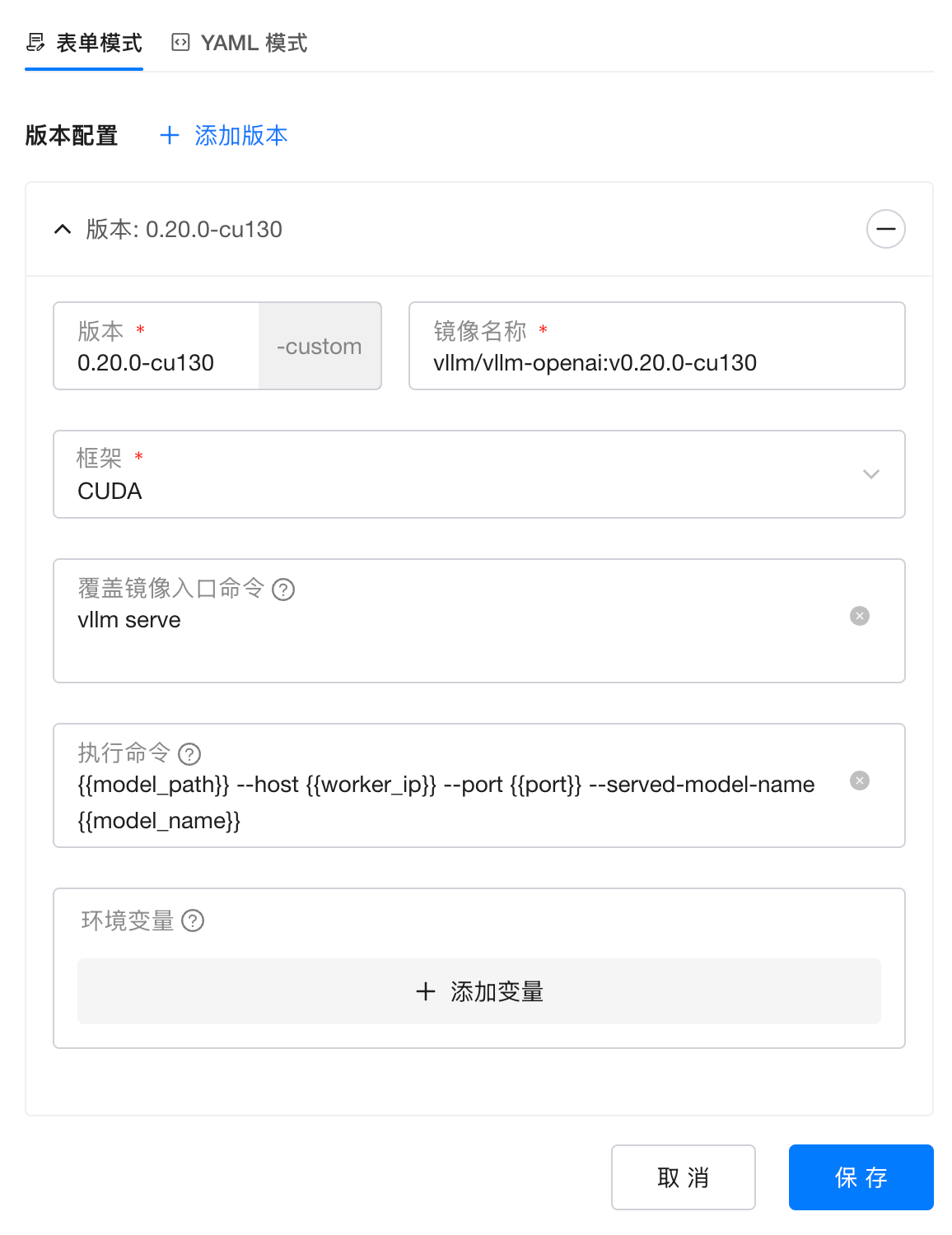
在推理后端菜单,编辑 vLLM,在版本配置中选择添加版本,添加一个新的 vLLM 版本,指向 vLLM 官方镜像:
| 配置 | 值 |
|---|---|
| 版本 | 0.20.0-cu130 |
| 镜像名称 | vllm/vllm-openai:v0.20.0-cu130 |
| 框架 | CUDA |
| 覆盖镜像入口命令(ENTRYPOINT) | vllm serve |
| 执行命令 | {{model_path}} --host {{worker_ip}} --port {{port}} --served-model-name {{model_name}} |
自定义添加 vLLM 0.20.0-cu130 镜像配置如图所示:
注意:
- GPUStack 会自动调用主机容器运行时拉取容器镜像,需要确保 Worker 节点可访问 Docker Hub,或者提前拉取好并重新 tag,并按需修改 UI 配置中的镜像地址;
- 保持执行命令中的 {{}} 变量内容不变,此为模板化配置。
也可以切换到 YAML 模式,直接使用以下的 YAML 导入(公众号复制可能存在特殊格式,可以发送给 AI 重新整理 YAML 格式):
backend_name: vLLM
version_configs:
0.20.0-cu130-custom:
image_name: vllm/vllm-openai:v0.20.0-cu130
entrypoint: vllm serve
run_command: >-
{{model_path}} --host {{worker_ip}} --port {{port}} --served-model-name
{{model_name}}
env: {}
custom_framework: cuda
注意:如果当前已经有其它自定义版本,需要将其它自定义版本一同添加在 version_configs 中一起导入。
部署 DeepSeek V4 模型
vLLM 已提供关于 DeepSeek V4 模型的部署与使用教程,详情可参考:
https://recipes.vllm.ai/deepseek-ai/DeepSeek-V4-Pro
以下将介绍在 GPUStack 上部署 DeepSeek V4 Pro 模型的配置流程。
-
在在线环境下,可直接通过 HuggingFace 或 ModelScope 搜索
deepseek-ai/DeepSeek-V4-Pro模型并进行部署,具体步骤参考下方。 -
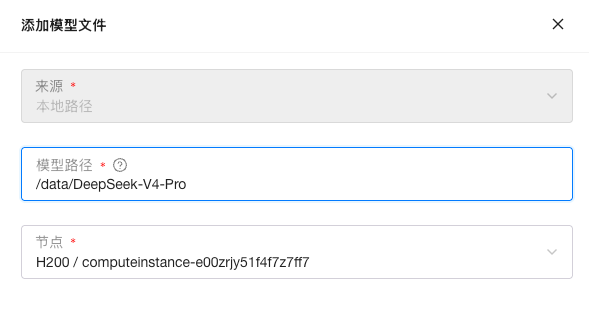
在离线环境中,需要提前下载好模型权重,并将其分发到 Worker 节点,同时挂载到对应的 Worker 容器中。随后,在 GPUStack 控制台 - 模型文件菜单中,选择添加模型文件 - 本地路径,填写对应的模型权重路径。需要注意,这里填写的应为容器内路径,例如:
联网环境:在 GPUStack 控制台 - 部署菜单下,选择 部署模型 → ModelScope,直接搜索 deepseek-ai/DeepSeek-V4-Pro 模型进行部署。
离线环境:可从 GPUStack 控制台 - 模型文件菜单中,选择已添加的 DeepSeek-V4-Pro 模型进行部署。
vLLM
-
后端:选择
vLLM -
版本:选择前面自定义添加的
0.20.0-cu130-custom -
GPU:8 块 H200/H20 141GB GPU
使用以下后端参数和环境变量启动,后端参数支持单行或多行形式(注意已设置 TP 8 DP 1,请确保有八块 GPU 可分配;其它环境请根据实际情况调整并行策略):
# 后端参数
--trust-remote-code
--kv-cache-dtype fp8
--block-size 256
--enable-expert-parallel
# 可选 --data-parallel-size 8
# TP 模式单请求速度高,DP 模式总吞吐量更高,详见下文测试数据
--tensor-parallel-size 8
--max-num-seqs 512
# 默认 8192,会有更佳的性能表现,但在显存资源不足时易发生 OOM
# 512 更稳定,但吞吐性能相对较差,详见下文测试数据
--max-num-batched-tokens 512
--no-enable-flashinfer-autotune
--compilation-config '{"mode": 0, "cudagraph_mode": "FULL_DECODE_ONLY"}'
--gpu-memory-utilization 0.95
# auto 表示自动根据模型最大上下文设置上下文大小
# 注意 H200/H20 141G 设置 1M 上下文时,可用 KV cache 空间难以支撑高并发
# 期望服务更稳定,可以考虑设置上下文到:131072/262144/524288
# 或者考虑双机推理,或者开启扩展 KV 缓存(LMCache/HiCache)
--max-model-len auto
--tokenizer-mode deepseek_v4
--tool-call-parser deepseek_v4
--enable-auto-tool-choice
--reasoning-parser deepseek_v4
# 注意目前 H200/H20 开启 MTP 推测解码存在 Bug,无法启动则需要暂时移除该参数
# 04.27 更新:该参数需要设置为 1
# 04.28 更新:最新的 0.20.0 版本已支持解码 token > 2
--speculative_config '{"method":"mtp","num_speculative_tokens":1}'
# 环境变量
VLLM_ENGINE_READY_TIMEOUT_S=3600
等待模型启动时,可以在操作中点击查看日志,实时观察启动过程:
当模型实例状态显示为 Running 时,说明模型已经成功启动,可以进行后续的测试。
模型测试
试验场
-
TP 8 + EP:单请求 68 Tokens/s
-
DP 8 + EP:单请求 43 Tokens/s
考虑初始支持,MTP 推测解码等推理加速也尚未启用,后续还有优化空间:
基准测试
通过 GPUStack 提供的基准测试功能对模型进行一键性能压测:
发起吞吐测试
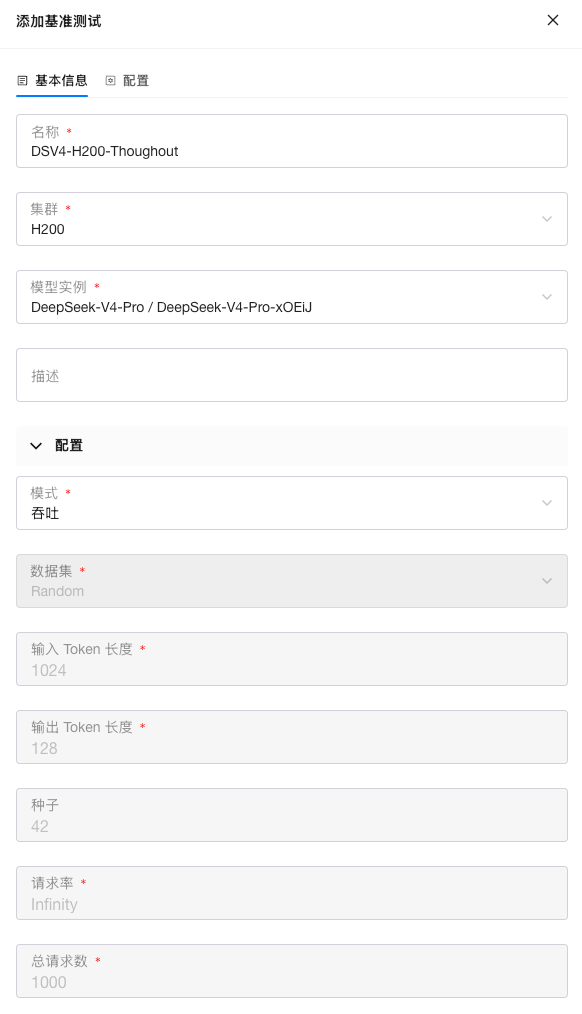
发起延迟测试
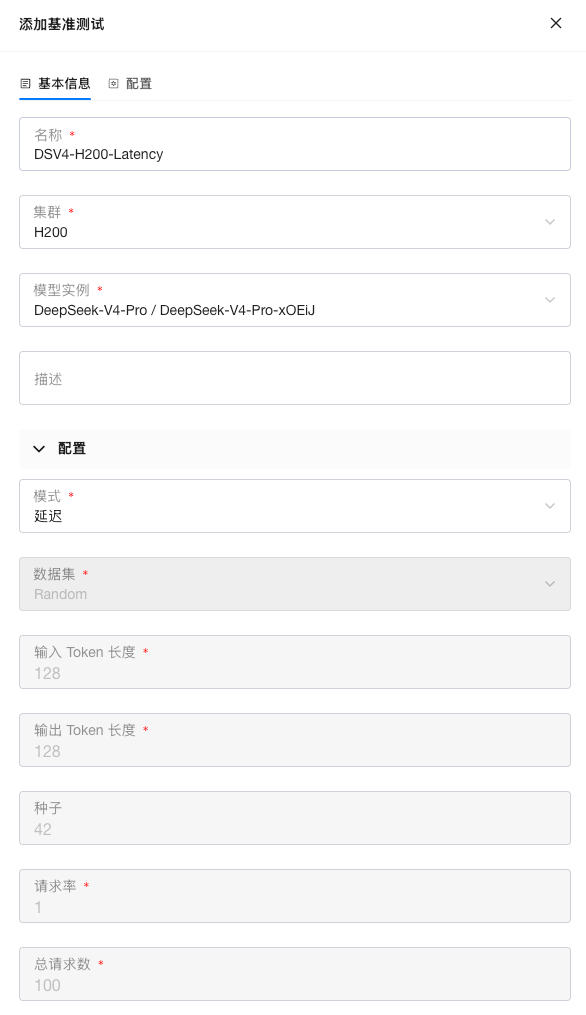
压测环境
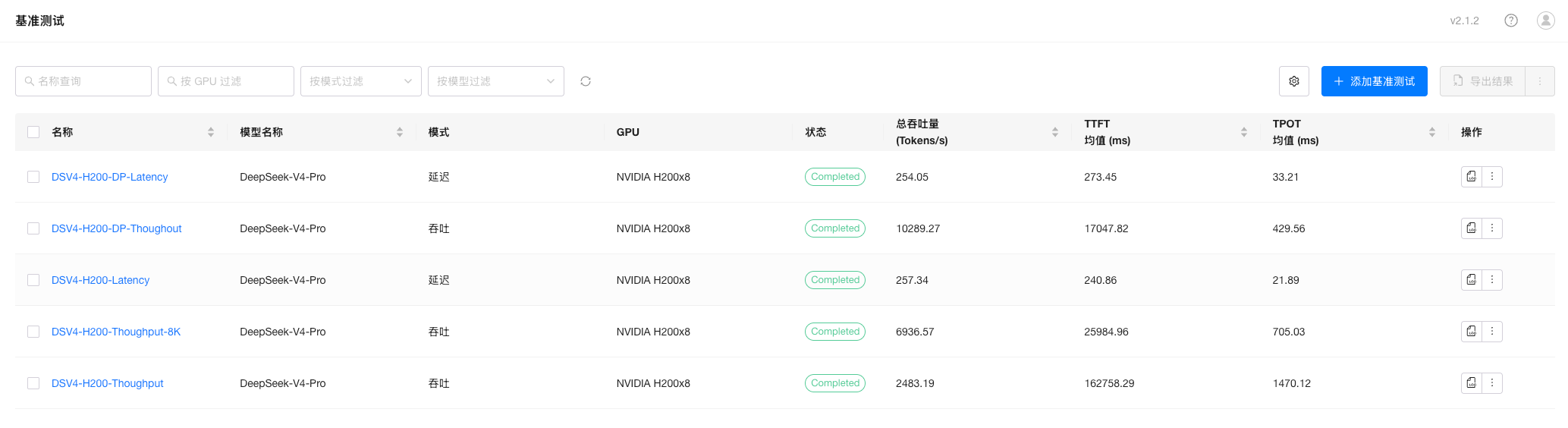
测试结果汇总
- 吞吐
| 差异调优参数 | 总吞吐(Tokens/s) |
|---|---|
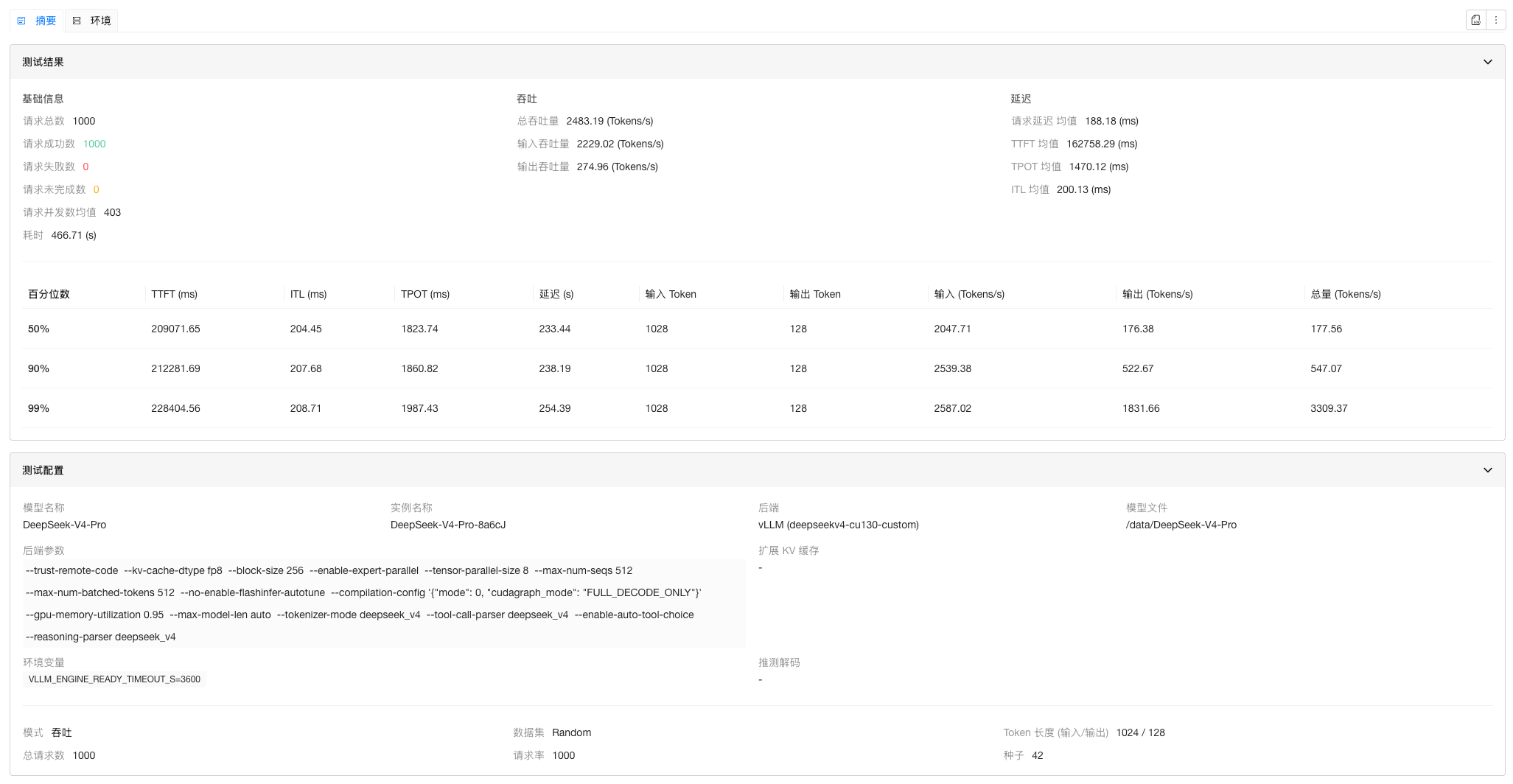
| TP 8 + EP + max-num-batched-tokens 512 | 2483.19 |
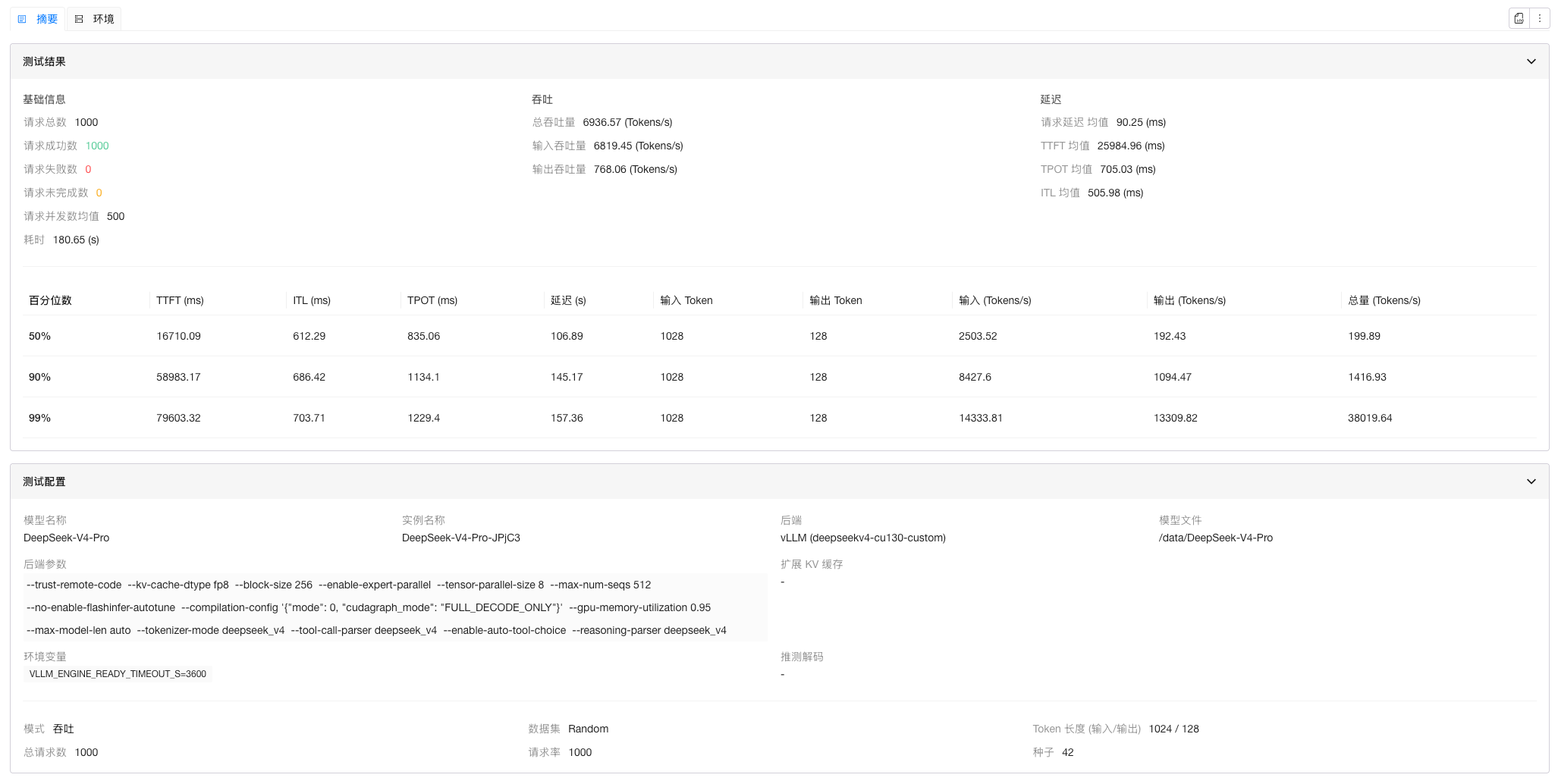
| TP 8 + EP + max-num-batched-tokens 8192 | 6936.57 |
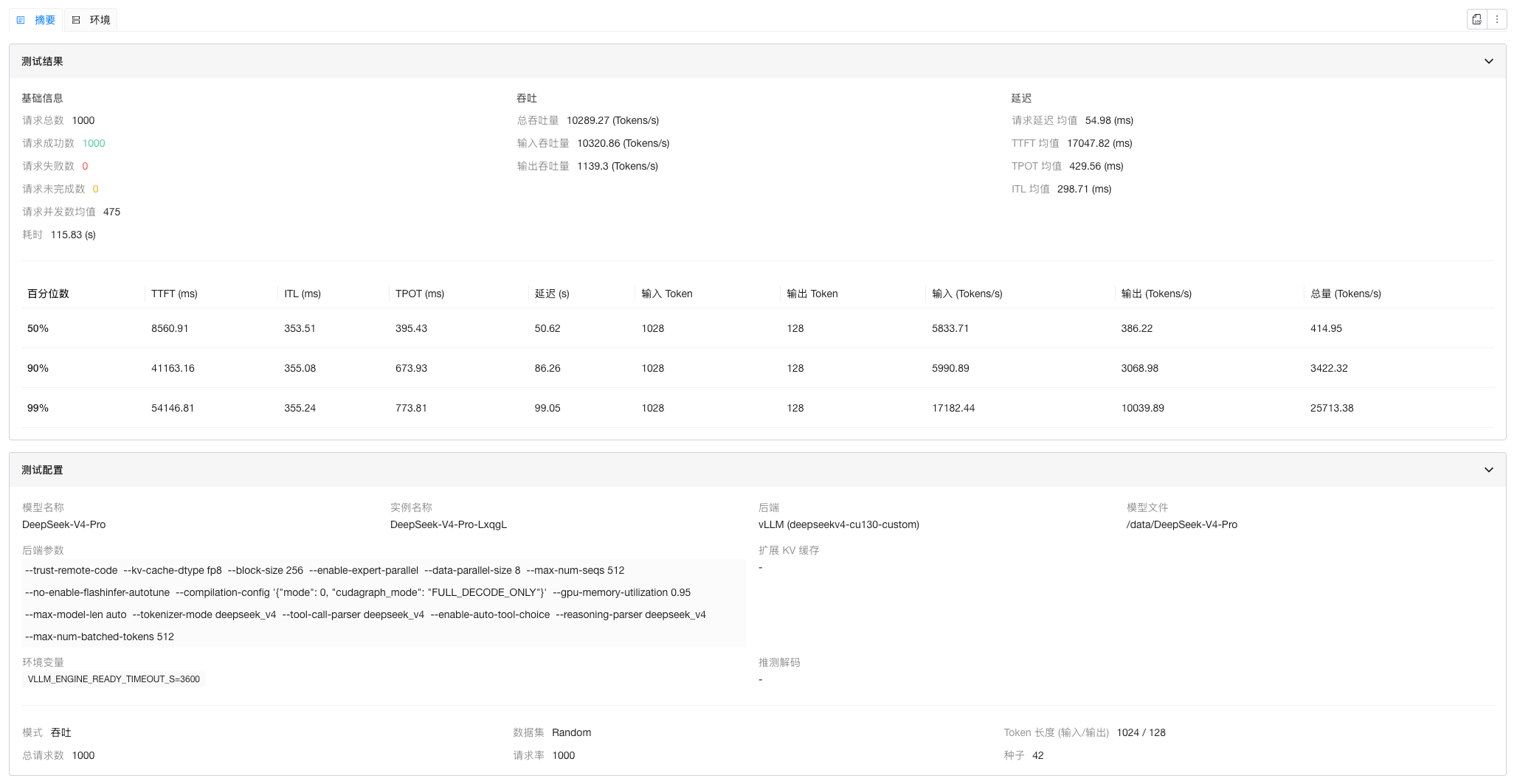
| DP 8 + EP + max-num-batched-tokens 512 | 10289.27 |
| DP 8 + EP + max-num-batched-tokens 8192 | OOM |
- 延迟
| 差异调优参数 | TTFT | TPOT |
|---|---|---|
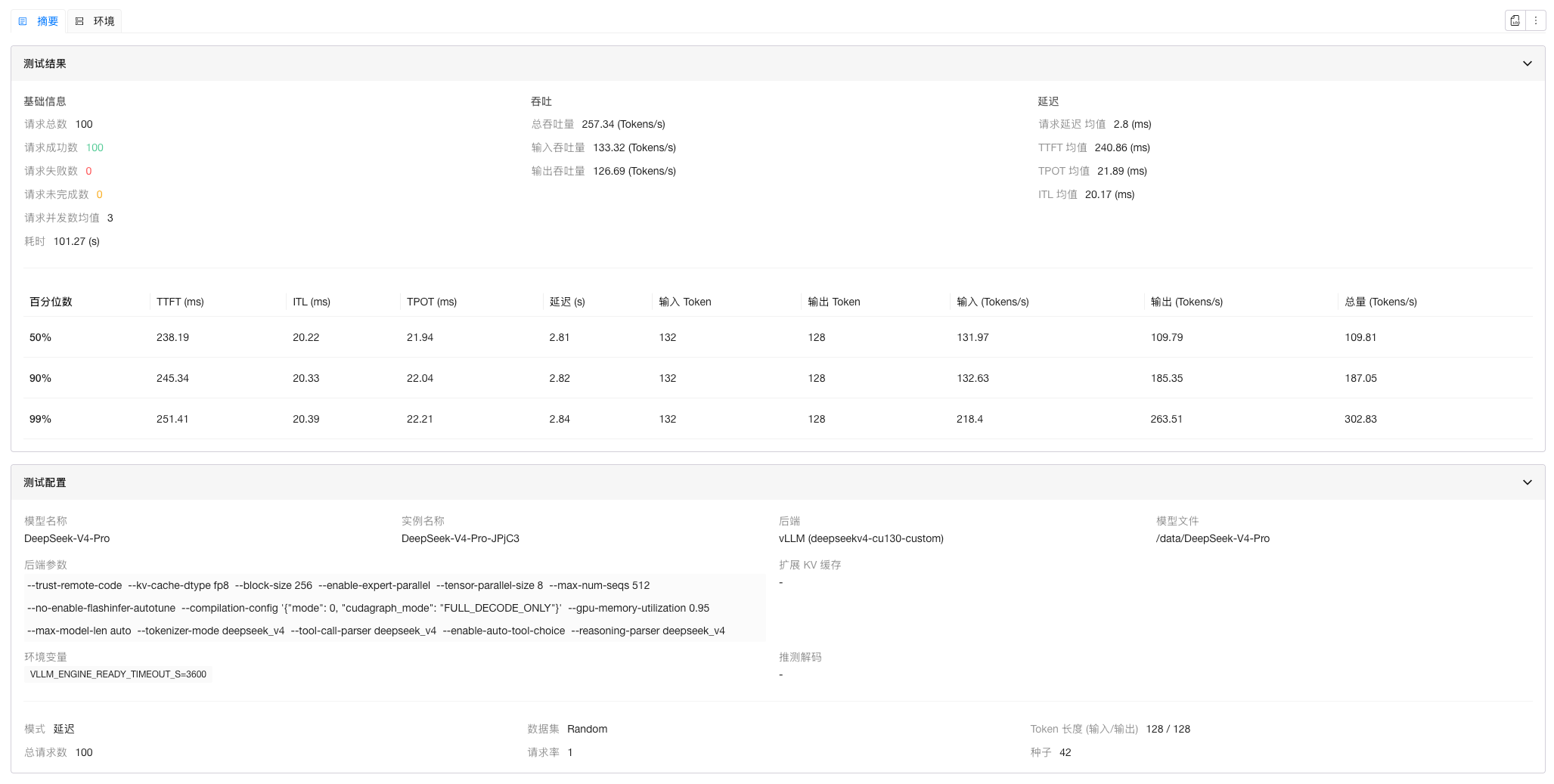
| TP 8 + EP | 240.86 | 21.89 |
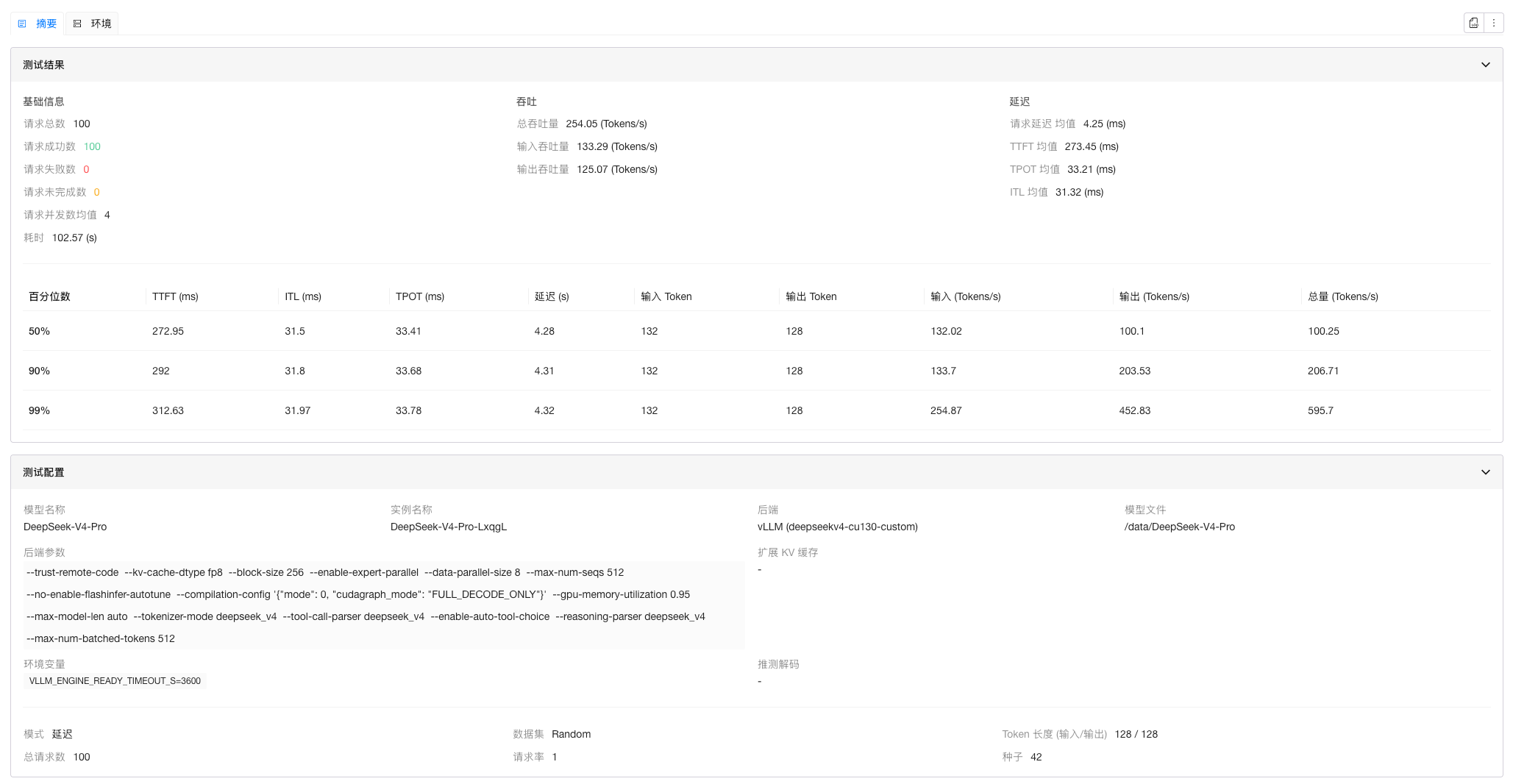
| DP 8 + EP | 273.45 | 33.21 |
压测记录截图
吞吐测试
- TP 8 + EP + max-num-batched-tokens 512
- TP 8 + EP + max-num-batched-tokens 8192
- DP 8 + EP + max-num-batched-tokens 512
延迟测试
- TP 8 + EP
- DP 8 + EP
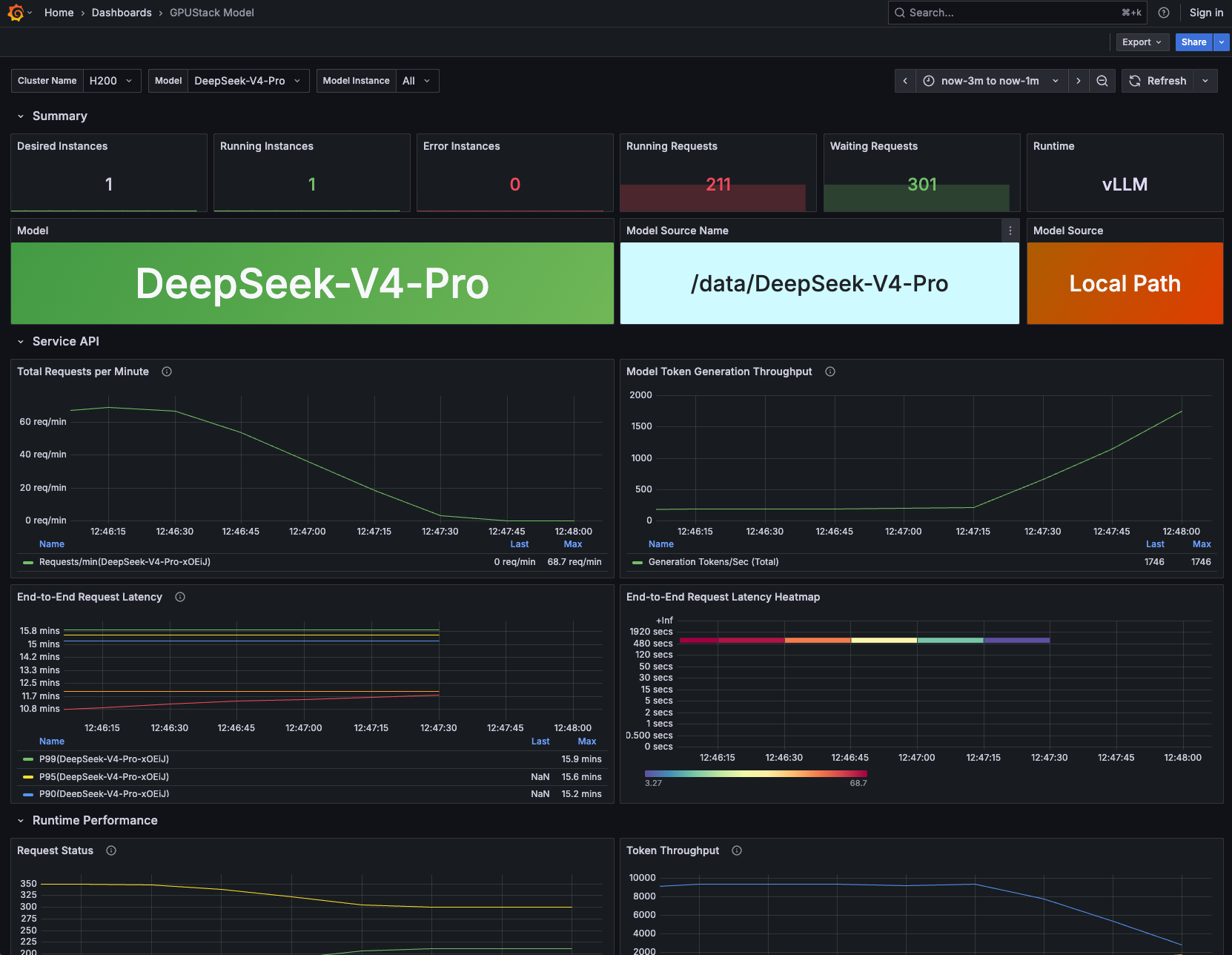
推理性能监控数据
API 调用
在 GPUStack 控制台 - 路由菜单中,选择对应模型,点击操作 → API 接入信息,即可查看模型 API 的调用说明:
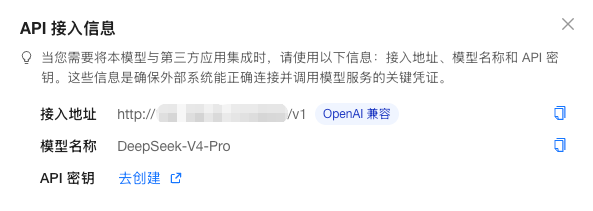
- 接入地址:统一通过 GPUStack 的认证 API 入口访问。
- 模型名称:调用时在请求中填写对应的 model。
- API 密钥:用于身份认证和权限校验。可按指引跳转到 API 密钥管理页面创建 API Key,并可设置访问控制,仅允许访问指定模型。
工具调用测试
安装 OpenAI 依赖:
pip install openai
创建测试 Python 脚本:
vim toolcalling.py
填写以下内容(注意根据实际环境修改 base_url、api_key 以及两处 model 参数):
from openai import OpenAI
import json
client = OpenAI(
base_url="http://89.169.122.242/v1",
api_key="gpustack_06933ce8d883fd33_a7c519ec4c7944c6d9ba302f6ecf6d8f"
)
# Define tools
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name, e.g. 'San Francisco, CA'"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "Temperature unit"
}
},
"required": ["location"]
}
}
}
]
# Step 1: Send user message with tools
response = client.chat.completions.create(
model="DeepSeek-V4-Pro",
messages=[
{"role": "user", "content": "What is the weather in Tokyo today?"}
],
tools=tools,
max_tokens=1024
)
message = response.choices[0].message
# Step 2: Process tool calls
if message.tool_calls:
tool_call = message.tool_calls[0]
print(f"Tool: {tool_call.function.name}")
print(f"Args: {tool_call.function.arguments}")
# Step 3: Feed back tool result and get final answer
response = client.chat.completions.create(
model="DeepSeek-V4-Pro",
messages=[
{"role": "user", "content": "What is the weather in Tokyo today?"},
message, # assistant's tool call message
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps({"temperature": 22, "condition": "Partly cloudy", "unit": "celsius"})
}
],
tools=tools,
max_tokens=1024
)
print(f"\nFinal answer: {response.choices[0].message.content}")
进行测试:
python toolcalling.py
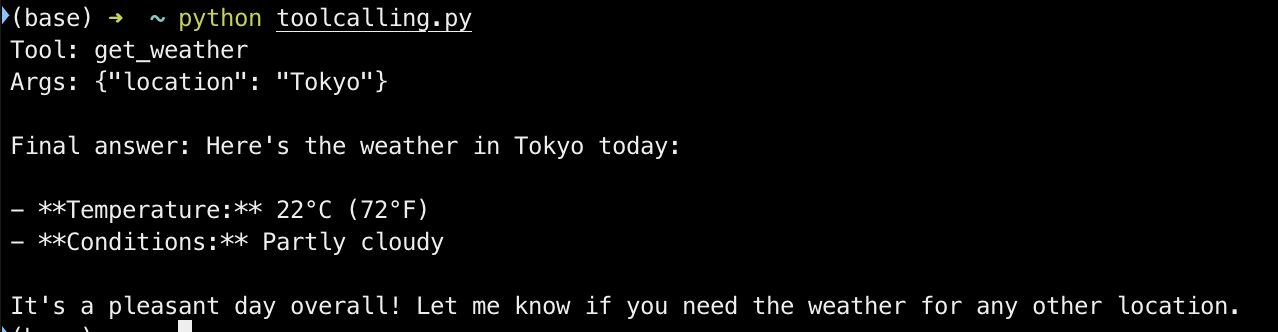
总结与生产调优建议
-
TP vs DP 的取舍
TP 模式单请求延迟更优(TTFT、TPOT 都更低),适合低并发、对响应速度敏感的场景;DP 模式可以显著提升整体吞吐(最高达到 10k+ Tokens/s),但延迟劣化明显,更适合高并发批处理或服务化场景。 -
max-num-batched-tokens 是关键的吞吐开关,但也是稳定性风险点
从 512 提升到 8192,吞吐提升接近 3 倍(TP)甚至更多,但在 DP 场景直接触发崩溃,说明该参数对显存和 KV Cache 压力极大。生产环境不建议盲目拉高,应结合显存水位逐步压测确定安全区间。 -
高并发下 OOM 是主要瓶颈,而不是算力不足
在 H200 / H20 141GB 环境中,真正限制系统稳定运行的不是算力,而是 KV Cache 空间。尤其在长上下文(如 1M)+ 高并发组合下,很容易出现显存耗尽问题。 -
上下文长度需要作为“硬约束”来控制
--max-model-len auto 在理论上更灵活,但在当前硬件条件下并不适合高并发生产。更现实的策略是限制在 131072 / 262144 / 524288 等区间,以换取更可控的稳定性。 -
并发能力需要通过“多维降压”来换稳定性
包括但不限于:降低 max-num-seqs、限制 max-num-batched-tokens、控制上下文长度,这三者本质是在争夺同一块 KV Cache 资源,需要整体权衡,而不是单点优化。 -
扩展 KV Cache(如 LMCache / HiCache)是重要方向
通过引入二级 KV Cache,可以有效缓解显存压力,是当前阶段提升稳定性的关键手段之一,尤其在显存不足 + 长上下文 + 高并发场景下价值明显。 -
MTP 推测解码当前不可用,实际性能仍未完全释放
进行部署测试时,在 H200 / H20 上,MTP 存在已知问题无法开启,这意味着推理性能还有一部分潜在提升空间尚未释放,目前最新版本已修复,推理速度还会有可观的提升。
整体结论:当前属于“可用但不宽松”的运行状态
H200 / H20 运行 DeepSeek V4 Pro 已经可以落地,但整体资源水位偏紧,对参数配置较为敏感。在追求高吞吐的同时,必须接受一定的稳定性约束。
工程建议:优先保证稳定,再逐步榨取性能
生产环境建议以“稳定运行”为第一目标,优先选择保守参数组合(如较低 batched tokens + 限制上下文),在稳定运行基础上逐步放大参数,通过压测找到最优平衡点,而不是一开始就追求极限吞吐。
加入 GPUStack 社区
GPUStack 社区聚焦 AI 基础设施与大模型实践。
社区中持续分享真实环境下的部署经验、问题排查案例,以及推理引擎、算力管理和系统架构相关讨论。
欢迎扫码加入 GPUStack 社区,与更多关注 AI Infra 与大模型推理实践的伙伴一起交流、学习与分享。
若群聊已满或二维码失效,请访问以下页面查看最新群二维码:
https://github.com/gpustack/gpustack/blob/main/docs/assets/wechat-group-qrcode.jpg
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
- # 【拾零】0 - 开箱即用的现代风终端 |Ghostty + Fish + Starship + fzf + zoxide + Raycast
- Redis--Set、ZSet操作命令和benchmark测试工具
- 异源数据同步 → 记一次 DataX 已同步数据量优化
- SourceGenerator之扑风捉影
- 【译】在 Visual Studio 中完全掌控您的悬浮窗口
- 当 CGO 遇见 Zig:一种更优雅的折腾方式,对比 GCC 后端
- NVIDIA H200/H20 DeepSeek-V4-Pro 部署指南、压测性能与稳定性调优建议
- 关于对wso2和keycloak的token交换的调研
- 内存化系统设计
- 《HelloGitHub》第 121 期
点击排行
本站推荐
